1. なぜデータを分けるのか?
前回、機械学習は「学習(fit)→ 推論(predict)」の2ステップだと学びました。 ここで大事な疑問が出てきます。「作ったモデルが、どれくらい賢いのかをどう確かめるの?」
学生のテストで考えてみましょう。試験前に「過去問の答えを丸暗記」した学生は、 まったく同じ問題が出れば満点を取れます。でも、それで「実力がある」と言えるでしょうか? 少し問題が変われば、解けないかもしれません。本当の実力は、「初めて見る問題」を解かせて初めて分かります。
機械学習も同じです。学習に使ったデータでテストすると、モデルの本当の実力は分かりません (答えを覚えているだけかもしれない)。そこで——
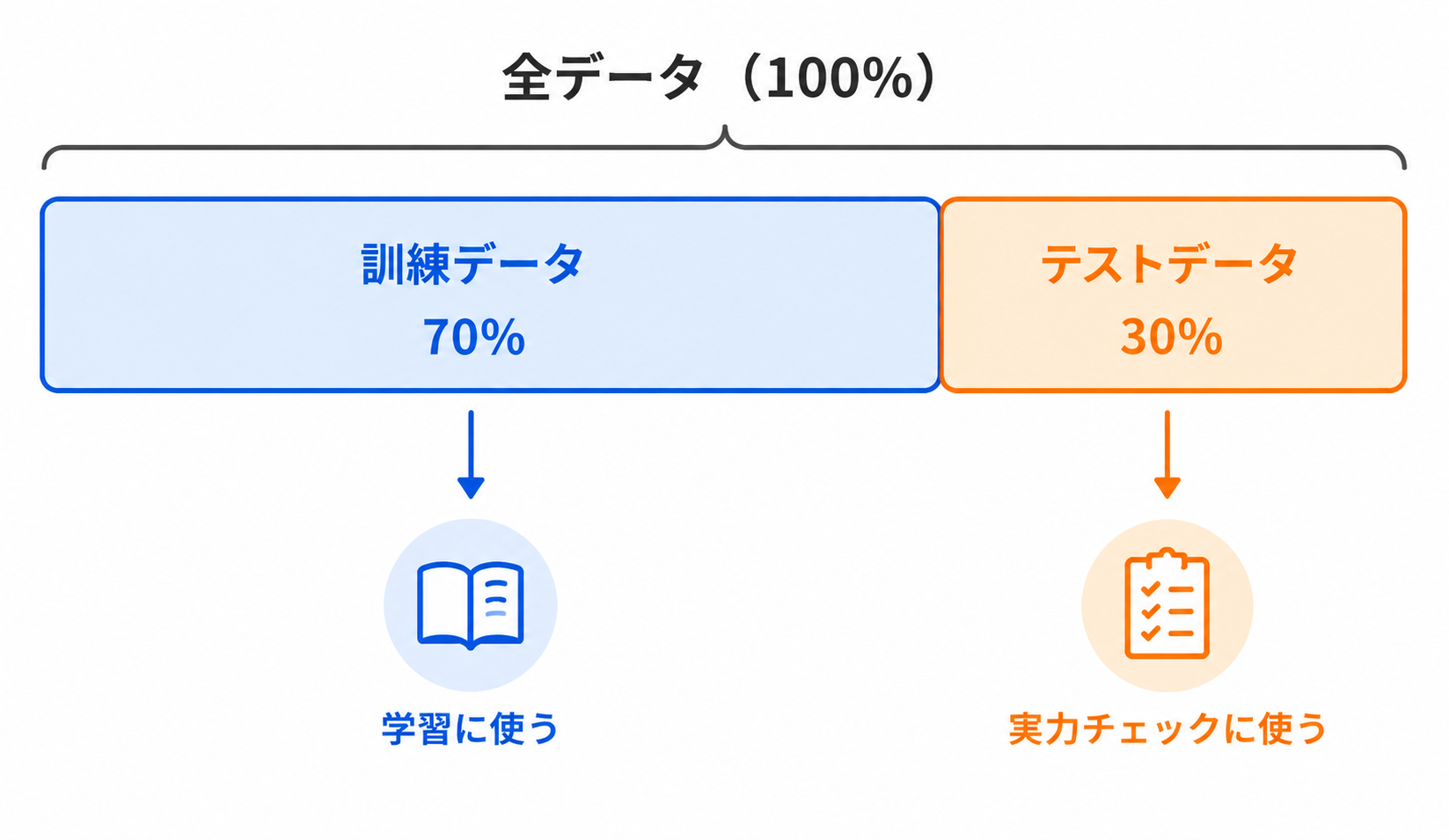
📌 データを2つに分ける:
- 訓練データ(training data)…モデルを学習させるために使う(問題集)
- テストデータ(test data)…学習には使わず取っておき、実力を測るために使う(初見の本番テスト)
テストデータは、モデルにとって「初めて見るデータ」。だからこそ本当の力が測れます。
2. 過学習(かがくしゅう)と汎化(はんか)
ここで、機械学習でとても大切な2つの言葉を覚えましょう。先ほどの「丸暗記」と「実力」の話そのものです。
| 用語 | 意味 | たとえ |
|---|---|---|
| 過学習(overfitting) | 訓練データを覚えすぎて、新しいデータに弱くなること | 過去問の丸暗記 |
| 汎化(generalization) | 新しいデータにも通用する力。機械学習が目指すゴール | 応用が利く実力 |
💡 ここがいちばん大事: 機械学習の目標は「訓練データで高得点」ではなく、「初めて見るデータでも良い予測ができる(=汎化)」ことです。 訓練データの点数だけが高くてテストデータの点数が低いとき、その状態を過学習と呼びます。 だからテストデータで評価することが欠かせないのです。 (過学習を防ぐ具体的な方法は レッスン11 で扱います)
3. train_test_split で分ける
scikit-learn には、データを訓練用とテスト用にランダムに分けてくれる便利な関数
train_test_split があります。これ1行で4つのかたまりに分かれます。
💡 2つの引数の意味:
test_size=0.3… 全体の30%をテスト用に(残り70%が訓練用)。569人なら テスト171人・訓練398人random_state=42… 分け方の「乱数のタネ」。同じ数字にすると毎回まったく同じ分け方になり、結果を再現できる(数字の42に深い意味はなく、慣習的によく使われます)
⚠ なぜ random_state を固定するの?:
指定しないと、実行のたびにランダムに分け方が変わり、結果(点数)が毎回ブレて比較できません。
random_state を固定すると、誰がいつ実行しても同じ結果になり、学習・比較・検証がしやすくなります。
このコースでは一貫して random_state=42 を使います。
4. 練習問題
糖尿病データを分割しよう
load_diabetes を読み込み、テストを20%(test_size=0.2、random_state=42)で分割し、
訓練データとテストデータの人数を表示してください。
ヒントを見る(答え+解説)
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
X, y = load_diabetes(return_X_y=True)
# test_size=0.2, random_state=42 で分割し、訓練・テストの人数を表示してください
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42)
print("訓練:", X_train.shape[0], "人") # 353
print("テスト:", X_test.shape[0], "人") # 89442人を 8:2 に分けると、訓練353人・テスト89人になります。test_size を変えるだけで割合を調整できます。
テストの割合を変えてみよう
乳がんデータを test_size=0.25(25%をテスト)で分割し、訓練・テストの人数を表示してください。 さきほどの30%のときと数が変わることを確かめましょう。
ヒントを見る(答え+解説)
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
X, y = load_breast_cancer(return_X_y=True)
# test_size=0.25, random_state=42 で分割し、訓練・テストの人数を表示してください
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42)
print("訓練:", X_train.shape[0], "人") # 426
print("テスト:", X_test.shape[0], "人") # 14325%をテストにすると、訓練426人・テスト143人。テストを増やすほど評価は安定しますが、学習に使えるデータは減ります。一般には7:3 や 8:2 がよく使われます。
random_state を固定すると再現できる
同じ random_state=42 で2回分割し、同じ分け方になることを確かめてください。
(下のコードを実行するだけでOK。出力が True になれば再現できている証拠です)
ヒントを見る(解説)
出力は 同じ分け方になった?: True になります。
random_state を同じ数字に固定すると、ランダムなはずの分割が毎回まったく同じになります。
試しに片方を random_state=1 に変えると False になり、分け方が変わるのが分かります。
再現性が大切な機械学習では、この「タネの固定」が基本です。
5. まとめ
このレッスンのポイント
- 学習に使ったデータでテストすると本当の実力は測れない → データを分ける
- 訓練データ=学習用/テストデータ=実力を測る初見データ
- 過学習=覚えすぎて新データに弱い/汎化=新データにも通用する力(ゴール)
train_test_split(X, y, test_size=0.3, random_state=42)で4つに分割random_stateを固定すると、毎回同じ分け方になり結果を再現できる
自由に試してみましょう:
完了するとコース一覧に進捗が記録されます