1. 過学習を「見える化」する
レッスン3で過学習(覚えすぎ)と汎化(応用力)を学びました。 ここではそれを実際の数字で確かめます。 決定木は、深くする(質問を増やす)ほど訓練データに合わせ込めます。やってみましょう。
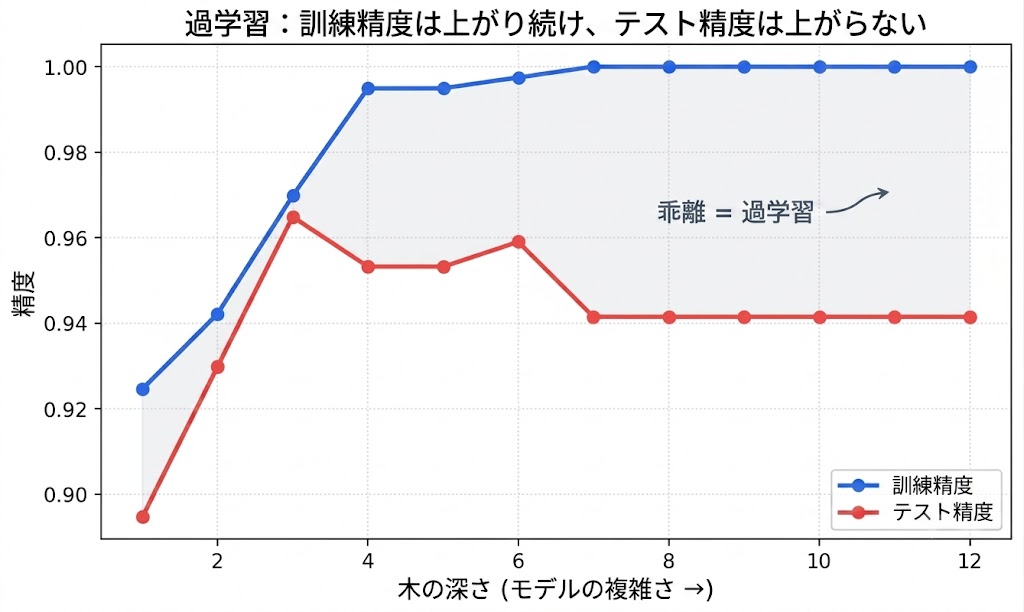
⚠ 「訓練の点数が高い=良いモデル」ではない: 深い木は訓練データを丸暗記して訓練精度1.0。でもテストは0.942で、浅い木(0.965)に負けています。 大事なのは訓練の点数ではなく、テスト(=初見データ)での点数=汎化性能。 モデルは複雑にしすぎないほうが良いことも多いのです。
2. 交差検証 — 評価のブレを抑える
ここで1つ問題があります。テストの点数は「たまたまの分け方」で上下します。 運よく簡単なデータがテストに入れば高く、難しいのが入れば低く出てしまう。これでは不安です。
そこで使うのが 交差検証(こうさけんしょう / cross-validation)。 データをk個のかたまりに分け、「1つをテスト・残りで学習」をk回くり返して平均します。 こうすると、1回きりの運に左右されない安定した評価が得られます。
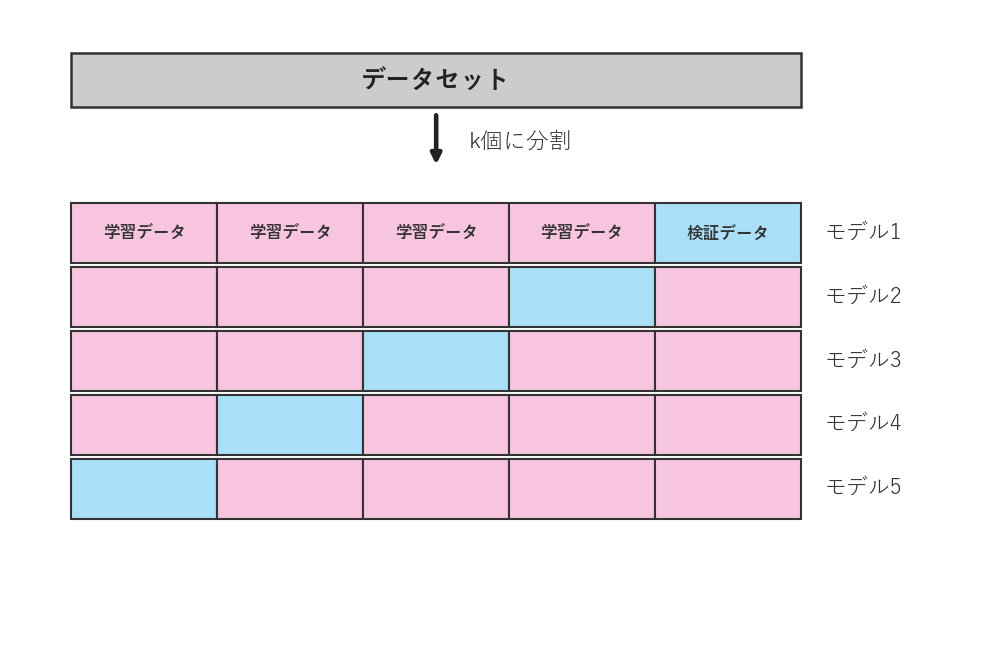
💡 なぜ平均で見るのか:
5回のスコアは 0.921〜0.982 とけっこう幅があります。もし1回だけ測って「0.921」だったら過小評価、「0.982」だったら過大評価です。
平均(0.956)を見ることで、モデルの“本当の実力”に近づけます。
cross_val_score(モデル, X, y, cv=5) の1行で済むのも便利です。
3. ハイパーパラメータを調整する
max_depth=3 の 3 のように、人があらかじめ決める設定を
ハイパーパラメータ(hyperparameter) と呼びます
(モデルが学習で見つける「係数」とは別もので、こちらは人間が選ぶ)。
良いハイパーパラメータを交差検証で選ぶのが定番です。
💡 「深いほど良い」ではない: 交差検証で比べると、max_depth=2 あたりが最も高く、深さ制限なし(過学習)はむしろ下がります。 ハイパーパラメータを調整して、過学習を抑えつつ汎化性能を最大化する——これが実務のモデル改善の基本動作です。 (本格的な自動調整 GridSearch などは E資格対策コース・医療AIコース で扱います)
💡 「1回だけ分けて測ったテスト精度(約0.96)」と「交差検証(約0.9〜0.93)」で数字が違うのはなぜ?: これはこのページ前半でやった“1回きりの分割”が、たまたま当てやすかっただけで、何度も測りなおす交差検証のほうが より正直な実力に近いからです。まさに、このセクションの冒頭で説明した「1回の分割は運でブレる」の実例です。 そのため、上のグラフ(1回の分割)では深さ3が良く見えても、交差検証では深さ2が最良、というように 評価方法によって“ベストな深さ”はずれることがあります。最終的な判断は、安定した交差検証で行うのが安全です。
4. 練習問題
過学習の差を確かめよう
深い決定木(制限なし)で、訓練の正解率とテストの正解率を両方表示し、その差(過学習)を見てください。
ヒントを見る(答え+解説)
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
model = DecisionTreeClassifier(random_state=42).fit(X_train, y_train)
# 訓練の正解率 と テストの正解率 を表示してください
print("訓練:", round(accuracy_score(y_train, model.predict(X_train)), 3)) # 1.0
print("テスト:", round(accuracy_score(y_test, model.predict(X_test)), 3)) # 0.942訓練1.0・テスト0.942。訓練だけ満点なのは、データを丸暗記した過学習のサインです。テストの点数こそが本当の実力です。
交差検証で評価しよう
ランダムフォレストを cross_val_score(cv=5)で評価し、5回のスコアの平均を表示してください。
ヒントを見る(答え+解説)
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
X, y = load_breast_cancer(return_X_y=True)
# RandomForest を cv=5 で交差検証し、平均スコアを表示してください
model = RandomForestClassifier(random_state=42)
scores = cross_val_score(model, X, y, cv=5)
print("平均スコア:", round(scores.mean(), 3)) # 0.956平均スコアは 0.956。5回の評価をならすことで、1回きりよりも信頼できる実力の見積もりになります。
最適な深さを探そう
決定木の max_depth を 1, 2, 3 と変えて交差検証し、いちばんスコアが高い深さを見つけてください。
ヒントを見る(答え+解説)
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeClassifier
X, y = load_breast_cancer(return_X_y=True)
# max_depth を 1,2,3 と変えて、交差検証スコアを表示してください
for depth in [1, 2, 3]:
model = DecisionTreeClassifier(max_depth=depth, random_state=42)
score = cross_val_score(model, X, y, cv=5).mean()
print(f"max_depth={depth}: {round(score, 3)}")
# max_depth=1: 0.9
# max_depth=2: 0.928 ← いちばん高い
# max_depth=3: 0.919この中では max_depth=2 が最高(0.928)。交差検証を使えば、こうしてデータに合った設定を客観的に選べます。
5. まとめ
このレッスンのポイント
- 過学習は「訓練の点数とテストの点数の差」で見える化できる
- 訓練だけ高くてテストが低い=過学習。大事なのはテスト(汎化)の点数
- 交差検証=データをk分割し、k回評価して平均(1回の運に左右されない)
cross_val_score(モデル, X, y, cv=5)で手軽に安定評価- ハイパーパラメータ(max_depthなど)は人が決める設定。交差検証で良い値を選ぶ
自由に試してみましょう:
完了するとコース一覧に進捗が記録されます