1. 教師なし学習 — 正解なしでグループを見つける
ここまで(回帰・分類)は、すべて「正解(ラベル)つき」のデータで学ぶ 教師あり学習 でした。 Unit 4では、まったく違うタイプ——教師なし学習(unsupervised learning) に進みます。 これは「正解がない」データから、自分でパターンや構造を見つける学習です。
その代表が クラスタリング(clustering)。 「似たもの同士を自動でグループ(クラスタ)に分ける」方法です。 グループの「正解」は与えません。データの近さだけを頼りに、自然なまとまりを見つけます。
🩺 医療データ文脈: たとえば「検査値が似ている患者を自動でグループ分け」すると、 これまで気づかなかった患者の“タイプ”が見えてくることがあります。 「正解(診断名)が分かっていなくても、データの傾向から集団を発見する」——これがクラスタリングの使いどころです。
2. k-means の仕組み — 4ステップで動く
クラスタリングの定番が k-means(k平均法) です。 名前にある「平均(means)」がカギで、「グループの中心(重心)を平均で求め、近い点をそこに割り当てる」—— この単純な作業をくり返すだけで、データのまとまりを見つけます。
身近なたとえで考えましょう。広場にいる人たちを、立ち位置をもとに 3つのグループに分けたいとします。
📋 k-means の4ステップ(k=3 の例):
- ① 重心を置く … 目印になる旗(重心)を3本、適当な場所に立てる
- ② 割り当てる … 各人はいちばん近い旗のグループに入る
- ③ 重心を動かす … 各グループの人の真ん中(平均の位置)へ旗を移動する
- ④ くり返す … 旗が動くと「近い旗」も変わる。②③を旗がほとんど動かなくなるまでくり返す
最後に旗が落ち着いた場所が各グループの中心(重心)。近くの人どうしが自然にまとまります。
💡 k-means の長所・短所:
- 長所:仕組みがシンプルで速い。大きなデータも扱いやすく、結果(重心)も解釈しやすい
- 短所:グループ数 k を自分で決める必要がある/最初の旗の位置(初期値)で結果が変わることがある
この「初期値による当たり外れ」を減らすため、scikit-learnの n_init は
初期位置を変えて何回か試し、いちばん良い結果を採用します(次のコードで使います)。
3. コードで動かす
上の4ステップは、scikit-learnの KMeans が内部で自動でやってくれます。
まず練習用の2次元データを make_blobs で用意し、k-means にかけてみましょう。
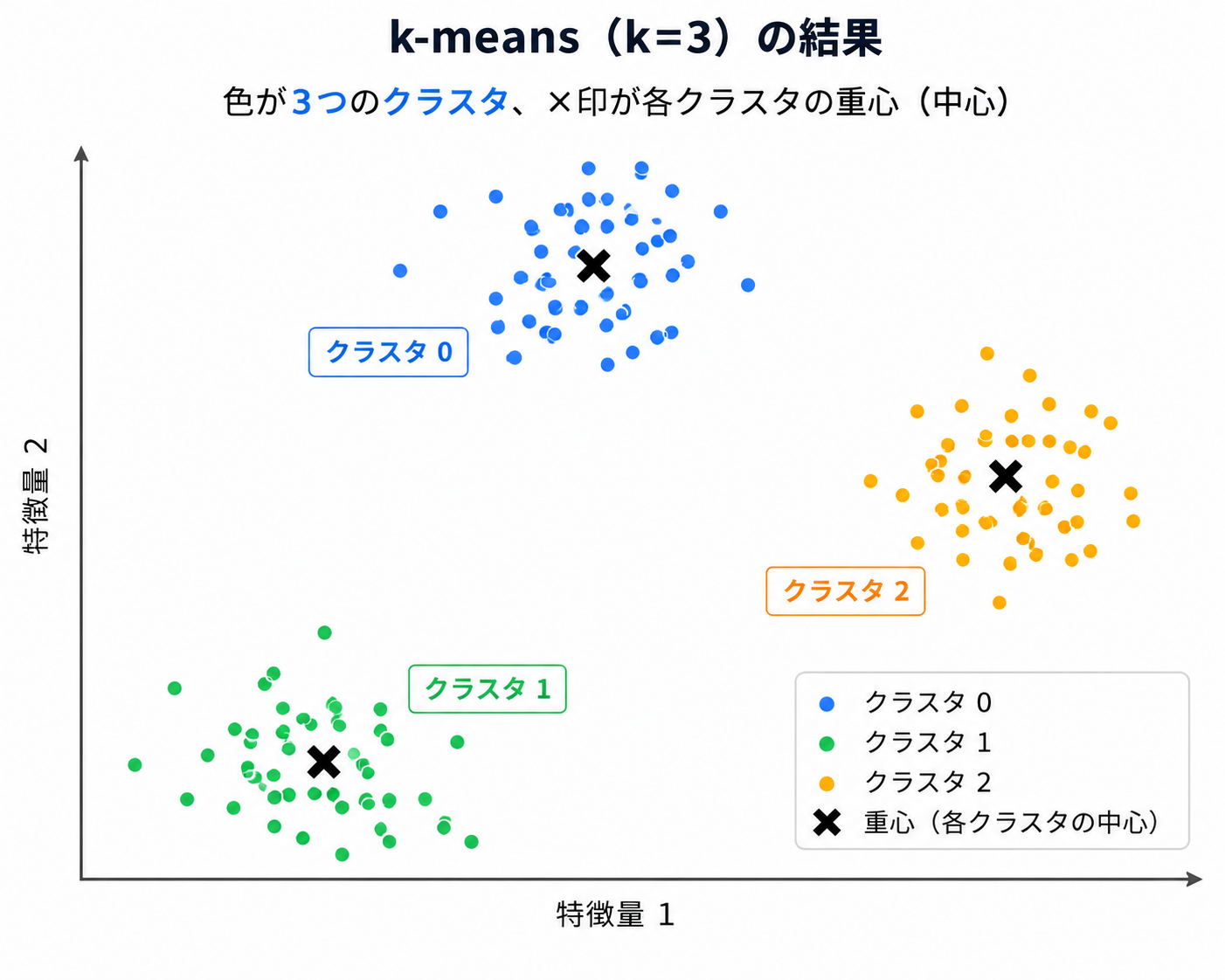
💡 教師あり学習との大きな違い:
fit(X) に正解 y を渡していないことに注目してください。
k-meansは「正解」を知らずに、点の近さだけで3つのまとまりを見つけました。
グループの番号(0,1,2)は便宜上のもので、「どれが何の病気か」は人間が後から解釈します。
4. 重心と、新しい点の割り当て
学習後のモデルには、各グループの重心(cluster_centers_)が入っています。
そして predict を使えば、新しい点がどのグループに入るかも分かります(いちばん近い重心のグループ)。
💡 クラスタリングに「正解率」はない: 分類と違い、クラスタリングには正解ラベルがないので、正解率では評価できません。 「分かれ方が自然か」「グループに意味づけできるか」を人間が確認したり、専用の指標で測ったりします。 k(グループ数)をいくつにするかも人が決める大事なポイントです(次の練習で試します)。
5. 練習問題
3グループに分けて人数を数えよう
make_blobs のデータを KMeans で3グループに分け、各グループの人数を表示してください。
ヒントを見る(答え+解説)
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
X, _ = make_blobs(n_samples=150, centers=3, cluster_std=1.0, random_state=42)
# KMeans(n_clusters=3) で分けて、各グループの人数を表示してください
model = KMeans(n_clusters=3, random_state=42, n_init=10).fit(X)
labels = model.labels_
for i in range(3):
print(f"グループ{i}:", int((labels == i).sum()), "人")
# それぞれ 50人ずつ3つのグループに50人ずつ、きれいに分かれます。今回のデータは3つのかたまりがはっきりしているので、k-meansが素直に見つけられました。
新しい点のグループを予測しよう
上のモデルで、新しい点 [-6, -7] がどのグループに入るかを predict で表示してください。
ヒントを見る(答え+解説)
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
X, _ = make_blobs(n_samples=150, centers=3, cluster_std=1.0, random_state=42)
model = KMeans(n_clusters=3, random_state=42, n_init=10).fit(X)
# 新しい点 [-6, -7] のグループを predict で表示してください
print(model.predict([[-6, -7]])[0])predict([[-6, -7]]) で、その点にいちばん近い重心のグループ番号が返ります。
重心の座標(sample_2で確認したもの)と見比べると、納得できるはずです。
グループ数 k を変えてみよう
同じデータを 4グループ(n_clusters=4)に分けて、各グループの人数を表示してください。 3つのかたまりを無理に4つに分けると、どうなるでしょう?
ヒントを見る(答え+解説)
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
X, _ = make_blobs(n_samples=150, centers=3, cluster_std=1.0, random_state=42)
# n_clusters=4 で分けて、各グループの人数を表示してください
model = KMeans(n_clusters=4, random_state=42, n_init=10).fit(X)
labels = model.labels_
for i in range(4):
print(f"グループ{i}:", int((labels == i).sum()), "人")
# 例:50, 39, 50, 11 のように、1つのかたまりが2分割される本来3つのかたまりなのに4つに分けるよう指示したので、1つのまとまりが無理やり2つに割られます。 k(グループ数)は人が決めるもので、データに合った数を選ぶことが大切だと分かります。
6. まとめ
このレッスンのポイント
- 教師なし学習=正解ラベルなしで、データの構造を見つける学習
- クラスタリング=似たもの同士を自動でグループ(クラスタ)に分ける
- k-means=k個のグループに、近い点を割り当てる(各グループに重心)
fit(X)に正解 y を渡さないのが教師ありとの大きな違い- 正解がないので「正解率」では測れない。k(グループ数)は人が決める
自由に試してみましょう:
完了するとコース一覧に進捗が記録されます