1. 決定木 — 質問を繰り返して分類する
これまでのロジスティック回帰は「直線(境界)」で区分を分けるモデルでした。 まったく違う発想のモデルが 決定木(decision tree) です。 これは「Yes / No の質問を繰り返して、答えにたどり着く」——いわばフローチャートです。
下は、乳がんデータで実際に作った決定木(深さ2)です。 「worst radius(最大半径)は16.795以下か?」という質問から始まり、枝分かれしながら「悪性/良性」を判定しています。
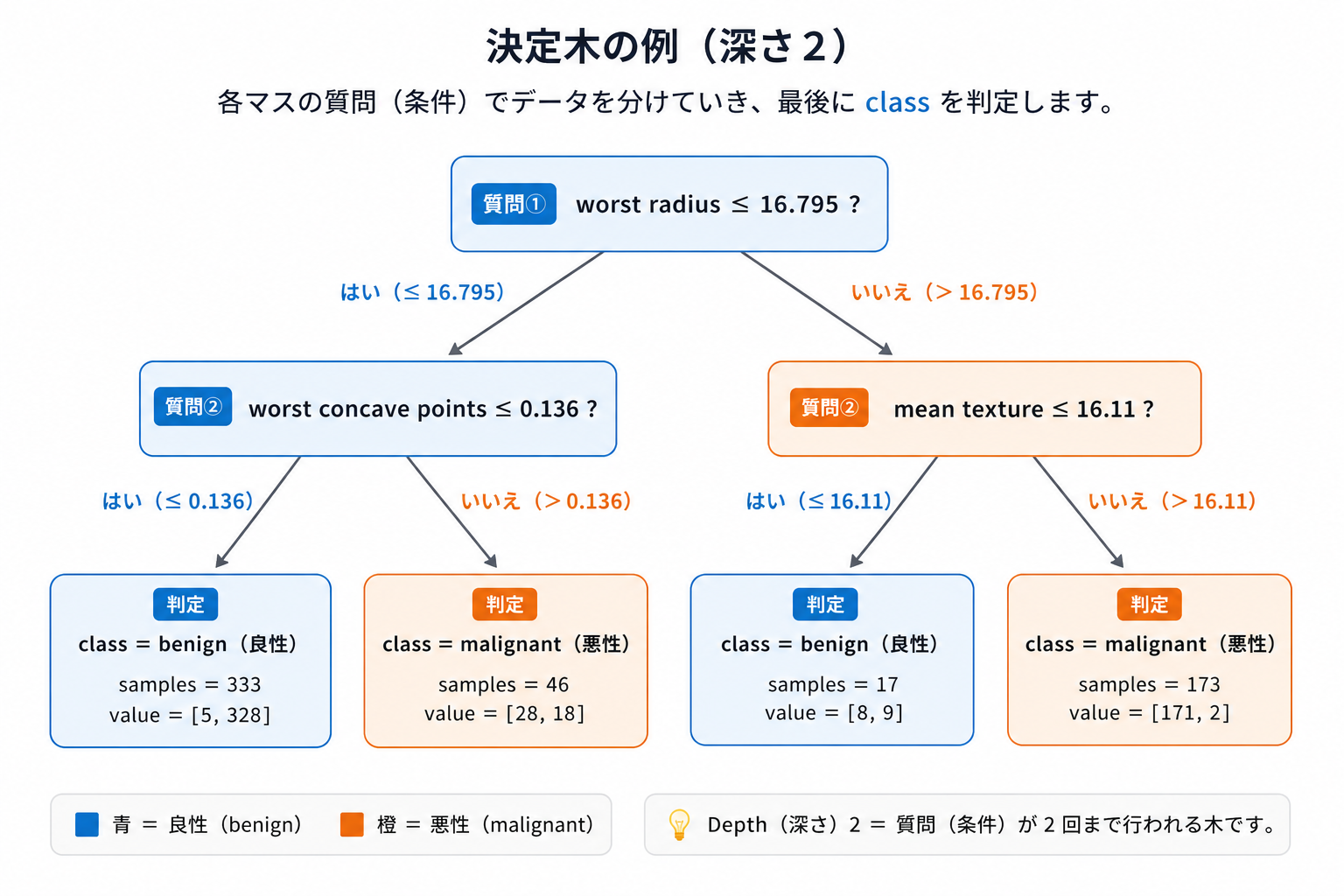
💡 決定木の特徴:
- 解釈しやすい…「なぜそう判断したか」を質問の流れで追える(医療で重要)
- 非線形な関係も扱える…直線では分けられない複雑な境界もOK
- 前処理(標準化)が不要…大小を比べるだけなので、スケールの影響を受けない
ただし1本の決定木は、データに合わせ込みすぎて過学習しやすい弱点があります。そこで——
2. ランダムフォレスト — 木をたくさん集める
1本の木が頼りないなら、たくさんの木を作って“多数決”すればいい——これが ランダムフォレスト(random forest) です。 少しずつ異なる木を何百本も育て、その予測を多数決でまとめます。 このように「複数のモデルを組み合わせて賢くする」仕組みを アンサンブル(ensemble) と呼びます。
💡 多数決で精度が上がった: 正解率が 0.942 → 0.971 に向上しました。1本の木より、たくさんの木の多数決のほうが安定して当たります。 「一人の意見より、大勢の意見のほうが信頼できる」のと同じ発想です。 ランダムフォレストはそこそこ手軽で精度も高いため、実務で最初に試される定番モデルのひとつです。
3. 特徴量の重要度(どの手がかりが効いた?)
ランダムフォレストには、もう一つ便利な機能があります。
feature_importances_ を見ると、「予測にどの特徴量がよく効いたか」が分かります。
医療では「何が診断の決め手だったのか」を知る手がかりになります。
🩺 重要度が分かると何が嬉しい?: 「mean concave points(細胞核のへこみ具合)」などが診断に強く効いている、と分かります。 どの検査項目が判断の決め手かが見えると、医療者の納得感が高まり、不要な検査を減らすヒントにもなります。 「予測できる」だけでなく「理由が見える」のは、医療AIで特に価値のある性質です。
4. 練習問題
ここでは解説とは別のデータ「ワインの成分データ」(scikit-learn同梱・医療以外)を使います。 学んだ手順が初めてのデータにもそのまま通用することを、自分の手で確かめましょう。 ワインは 13成分から3品種(class_0/1/2)を当てる多クラス分類です。
決定木で分類しよう
ワインの成分データ(load_wine)で DecisionTreeClassifier を学習させ、テストの正解率を表示してください。
(分割は test_size=0.3, random_state=42、モデルも random_state=42)
ヒントを見る(答え+解説)
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
X, y = load_wine(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 決定木を学習し、正解率を表示してください
model = DecisionTreeClassifier(random_state=42).fit(X_train, y_train)
pred = model.predict(X_test)
print("正解率:", round(accuracy_score(y_test, pred), 3)) # 0.963決定木の正解率は 0.963。これは3品種の多クラス分類ですが、コードは乳がん(2クラス)のときとまったく同じ。木モデルは標準化なしでOKです。
ランダムフォレストと比べよう
同じワインデータで RandomForestClassifier を学習させ、正解率が決定木より上がることを確かめてください。
ヒントを見る(答え+解説)
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
X, y = load_wine(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# ランダムフォレストを学習し、正解率を表示してください
model = RandomForestClassifier(random_state=42).fit(X_train, y_train)
pred = model.predict(X_test)
print("正解率:", round(accuracy_score(y_test, pred), 3)) # 1.0ランダムフォレストは 1.0。決定木(0.963)より高精度です。別データ(ワイン)でも、多数決(アンサンブル)で精度が上がることが確認できました。
重要な特徴量トップ3を出そう
ランダムフォレストの feature_importances_ を使って、ワインの品種判定に効いた特徴量トップ3を表示してください。
ヒントを見る(答え+解説)
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
d = load_wine()
X_train, X_test, y_train, y_test = train_test_split(d.data, d.target, test_size=0.3, random_state=42)
model = RandomForestClassifier(random_state=42).fit(X_train, y_train)
# 重要度の高い特徴量トップ3を表示してください
pairs = list(zip(model.feature_importances_, d.feature_names))
pairs.sort(reverse=True)
for importance, name in pairs[:3]:
print(name, round(importance, 3))
# color_intensity 0.18
# flavanoids 0.166
# alcohol 0.142トップは color_intensity(色の濃さ)や flavanoids(ポリフェノールの一種)など。
重要度を見ると、どの成分が品種の決め手になったかが分かります。
5. まとめ
このレッスンのポイント
- 決定木=Yes/Noの質問を繰り返して分類(フローチャート型)。解釈しやすく非線形もOK
- 木モデルは標準化(前処理)が不要(大小を比べるだけ)
- 1本の木は過学習しやすい → ランダムフォレスト(木の多数決=アンサンブル)で安定・高精度
- 正解率が 0.942 → 0.971 に向上(多数決の効果)
feature_importances_で「どの特徴量が効いたか」が分かる(理由が見える)
自由に試してみましょう:
完了するとコース一覧に進捗が記録されます