1. 「正解率だけ」では危ない
前回、分類モデルの正解率(accuracy)は98%でした。高そうに見えます。でも—— 正解率は、ときに人をだます指標です。極端な例で確かめましょう。
ある病気の検査を考えます。1000人中、本当に病気なのは50人(5%)だけ。 ここで「全員を“健康”と判定するだけ」のいい加減なモデルを作るとどうなるでしょう?
⚠ これが「正解率の罠」: 何もしていないモデルが正解率95%。でも病気の人を1人も見つけられていません(再現率0%)。 データに偏り(病気が少数)があると、正解率は簡単に高く見えてしまうのです。 だから分類では、正解率以外の指標でモデルを多面的に評価します。
2. 混同行列
分類の結果を細かく見るための表が 混同行列(confusion matrix) です。 「実際」と「予測」を突き合わせ、4種類の結果に分けて数えます。 病気を「陽性(見つけたいもの)」とすると、次の4マスになります。
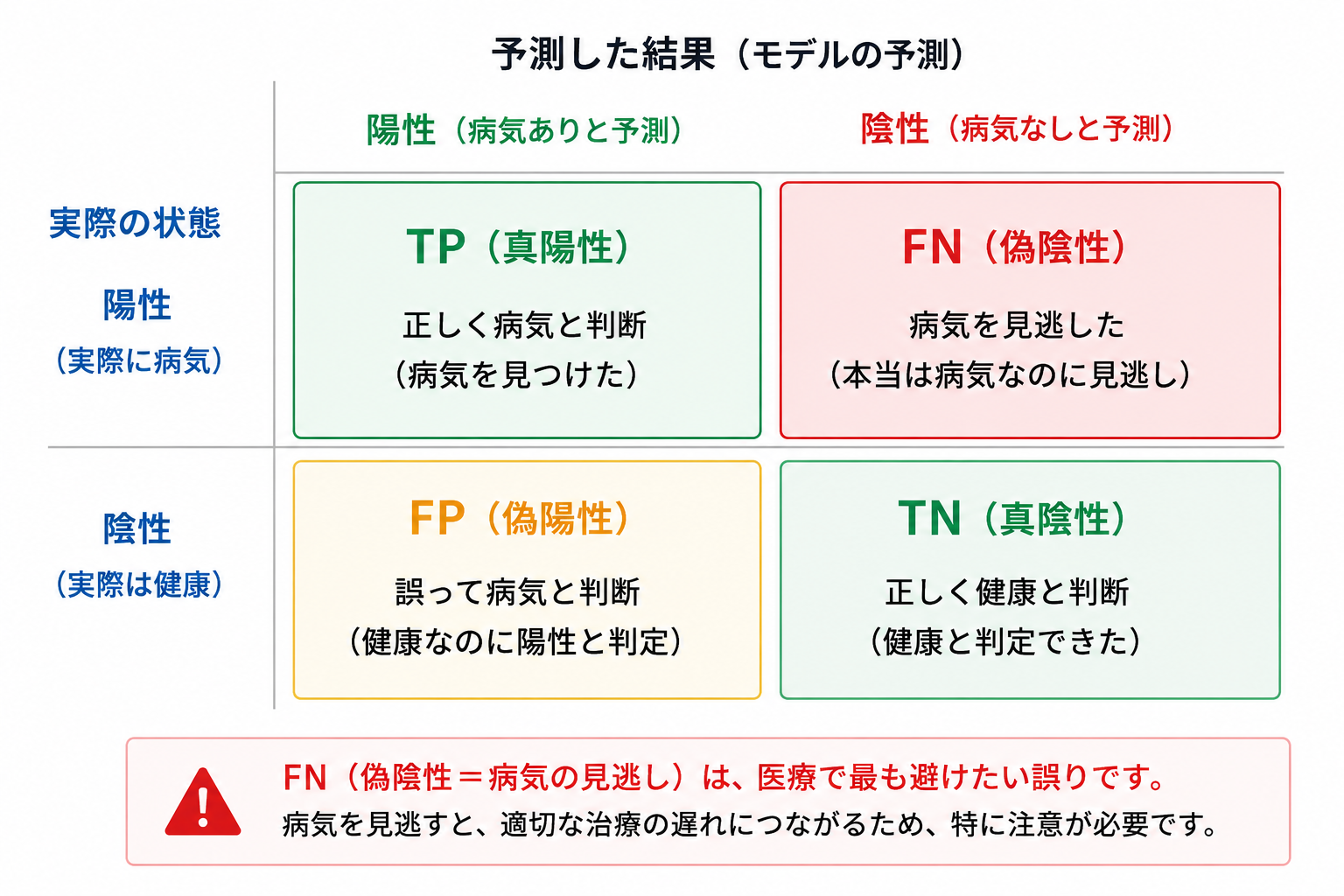
| 記号 | 名前 | 意味 |
|---|---|---|
| TP | 真陽性 | 病気の人を、正しく「病気」と判定(正解) |
| FN | 偽陰性 | 病気の人を、誤って「健康」と判定(=見逃し) |
| FP | 偽陽性 | 健康な人を、誤って「病気」と判定(=過剰な警告) |
| TN | 真陰性 | 健康な人を、正しく「健康」と判定(正解) |
実際のモデルで混同行列を出してみましょう。前回(レッスン7)とは逆に、ここでは見つけたい「悪性」を陽性(1)として扱います(医療では「見つけたい病気=陽性」と置くのが自然だからです)。
💡 y = (y0 == 0).astype(int) って何をしている?:
元データは「悪性=0 / 良性=1」。これを悪性=1(陽性)に置き換えるための1行です。2段階に分けると分かりやすいです。
y0 == 0… 各患者が「悪性か?」をTrue / Falseの並びで表す(悪性ならTrue).astype(int)… そのTrue / Falseを1 / 0に変換する(True→1、False→0)
結果、悪性だった人が1(陽性)、良性が0(陰性)になります。
🩺 このモデルは「見逃し」が1人: 悪性63人のうち、62人を正しく悪性と判定(TP)、1人を見逃した(FN)。 また、健康な人2人を誤って悪性と判定(FP)しています。 医療ではFN(見逃し)を限りなく減らしたい——たとえFP(過剰警告)が少し増えても、 病気を見逃すよりはマシ、と考えるのが基本です。
3. 適合率・再現率・F1スコア
混同行列の4マスから、3つの便利な指標が計算できます。どれも0〜1で、1に近いほど良いです。
| 指標 | 意味(ざっくり) | 気にする場面 |
|---|---|---|
| 適合率 (precision) | 「陽性」と予測したうち、本当に陽性だった割合 | 誤検知(FP)を減らしたいとき |
| 再現率 (recall) | 本当の陽性のうち、見つけられた割合 | 見逃し(FN)を減らしたいとき=医療で重視 |
| F1スコア | 適合率と再現率のバランス | 両方を総合的に見たいとき |
📐 式で書くと(混同行列の TP・FP・FN を使って):
- 適合率(precision) =
TP ÷ (TP + FP)… 陽性と予測した中で本当に陽性だった割合 - 再現率(recall) =
TP ÷ (TP + FN)… 実際の陽性の中で見つけられた割合 - F1スコア =
2 × 適合率 × 再現率 ÷ (適合率 + 再現率)… 2つの調和平均(バランス)
分子はどちらも TP(正しく当てた陽性)。分母が「陽性と予測した数(適合率)」か「実際の陽性の数(再現率)」かの違いです。
💡 再現率0.984の意味: 本当の悪性63人のうち、98.4%(62人)を見つけられたということ。 残り1.6%(1人)が見逃し(FN)です。医療AIでは、この再現率(見逃さない力)を特に高くしたい場面が多いです。 ただし再現率を上げようとFPが増える(過剰警告が増える)こともあり、適合率とのバランス(F1)も見ます。
4. 練習問題
混同行列を出して見逃しを数えよう
下記の実際と予測(1=陽性)から混同行列を作り、表示してください。 その後、偽陰性(FN=見逃し)が何人かをヒントで確認しましょう。
ヒントを見る(答え+解説)
from sklearn.metrics import confusion_matrix
y_true = [1, 1, 1, 0, 0, 1]
pred = [1, 0, 1, 0, 1, 1]
print(confusion_matrix(y_true, pred))
# [[1 1] ← 実際 陰性:1正解(TN), 1を陽性と誤り(FP)
# [1 3]] ← 実際 陽性:1を見逃し(FN), 3正解(TP)混同行列は [[1, 1], [1, 3]]。偽陰性(FN)は1人(右下より1つ左の値)。
実際は陽性だったのに「陰性」と予測してしまった人です。
適合率・再現率・F1を計算しよう
問題1と同じデータで、適合率・再現率・F1スコアを計算して表示してください。
ヒントを見る(答え+解説)
from sklearn.metrics import precision_score, recall_score, f1_score
y_true = [1, 1, 1, 0, 0, 1]
pred = [1, 0, 1, 0, 1, 1]
# 適合率・再現率・F1 を表示してください
print("適合率:", round(precision_score(y_true, pred), 3)) # 0.75
print("再現率:", round(recall_score(y_true, pred), 3)) # 0.75
print("F1:", round(f1_score(y_true, pred), 3)) # 0.75陽性予測4人のうち3人が正解 → 適合率0.75。実際の陽性4人のうち3人を発見 → 再現率0.75。 今回は両方0.75なのでF1も0.75になります。
「正解率の罠」を体験しよう
陽性が10%(100人中10人)のデータで、「全員を陰性と予測」したときの正解率と再現率を計算してください。 正解率は高いのに再現率はどうなるでしょう?
ヒントを見る(答え+解説)
from sklearn.metrics import accuracy_score, recall_score
y_true = [0] * 90 + [1] * 10 # 100人中10人が陽性
pred = [0] * 100 # 全員を陰性と予測
# 正解率と再現率を表示してください
print("正解率:", accuracy_score(y_true, pred)) # 0.9
print("再現率:", recall_score(y_true, pred)) # 0.0正解率は 0.9(90%)と高いのに、再現率は 0.0。陽性の人を1人も見つけられていません。
正解率が高い=良いモデル、とは限らない。とくに偏ったデータでは、再現率など複数の指標で確認することが大切です。
5. まとめ
このレッスンのポイント
- 偏ったデータでは正解率(accuracy)は当てにならない(正解率の罠)
- 混同行列で TP・FP・FN(見逃し)・TN の4種類に分けて見る
- 適合率=陽性予測の正しさ/再現率=陽性の見つけ率(見逃しの少なさ)
- F1スコア=適合率と再現率のバランス
- 医療ではFN(偽陰性=見逃し)を減らす=再現率を高めるのが特に重要
自由に試してみましょう:
💡 classification_report の表に出る見慣れない言葉(軽く知っておけばOK):
各区分(良性/悪性)ごとに precision・recall・f1-score が並びます。それに加えて——
support… その区分の件数(テストに何人いたか)macro avg… 各区分の指標の単純平均weighted avg… 件数(support)で重みづけした平均
いまは「そういう要約の行も出るんだな」程度の理解で大丈夫です。
完了するとコース一覧に進捗が記録されます