1. 「分類」=区分を当てる
ここまでは数値を予測する 回帰 を学んできました。Unit 3からは 分類(classification) に進みます。 分類とは、「どの区分(カテゴリ)に当てはまるか」を当てる問題です。
- 回帰…数値を予測(例:血圧は何mmHg?)
- 分類…区分を予測(例:この腫瘍は悪性か良性か?)
特に、答えが2択のものを 二値分類(binary classification) と呼びます。 「悪性/良性」「陽性/陰性」「再発する/しない」など、医療の現場には二値分類がたくさんあります。 今回は乳がんデータで「悪性(0)か良性(1)か」を予測してみましょう。
2. ロジスティック回帰 — 確率で答える
二値分類のいちばん基本的なモデルが ロジスティック回帰(logistic regression) です。
⚠ 名前に注意: 「回帰」という名前が付いていますが、ロジスティック回帰は“分類”のモデルです。 紛らわしいですが、「数値を予測する線形回帰」とは別物。区分(クラス)を予測するためのモデル、と覚えてください。
ロジスティック回帰のポイントは、いきなり「悪性/良性」と決めつけるのではなく、まず「確率」で答えることです。 「この患者が良性である確率は88%」のように出してから、0.5(50%)を境に区分を決めます。 この「数値を0〜1の確率に変換する」役割をするのが シグモイド関数 です。
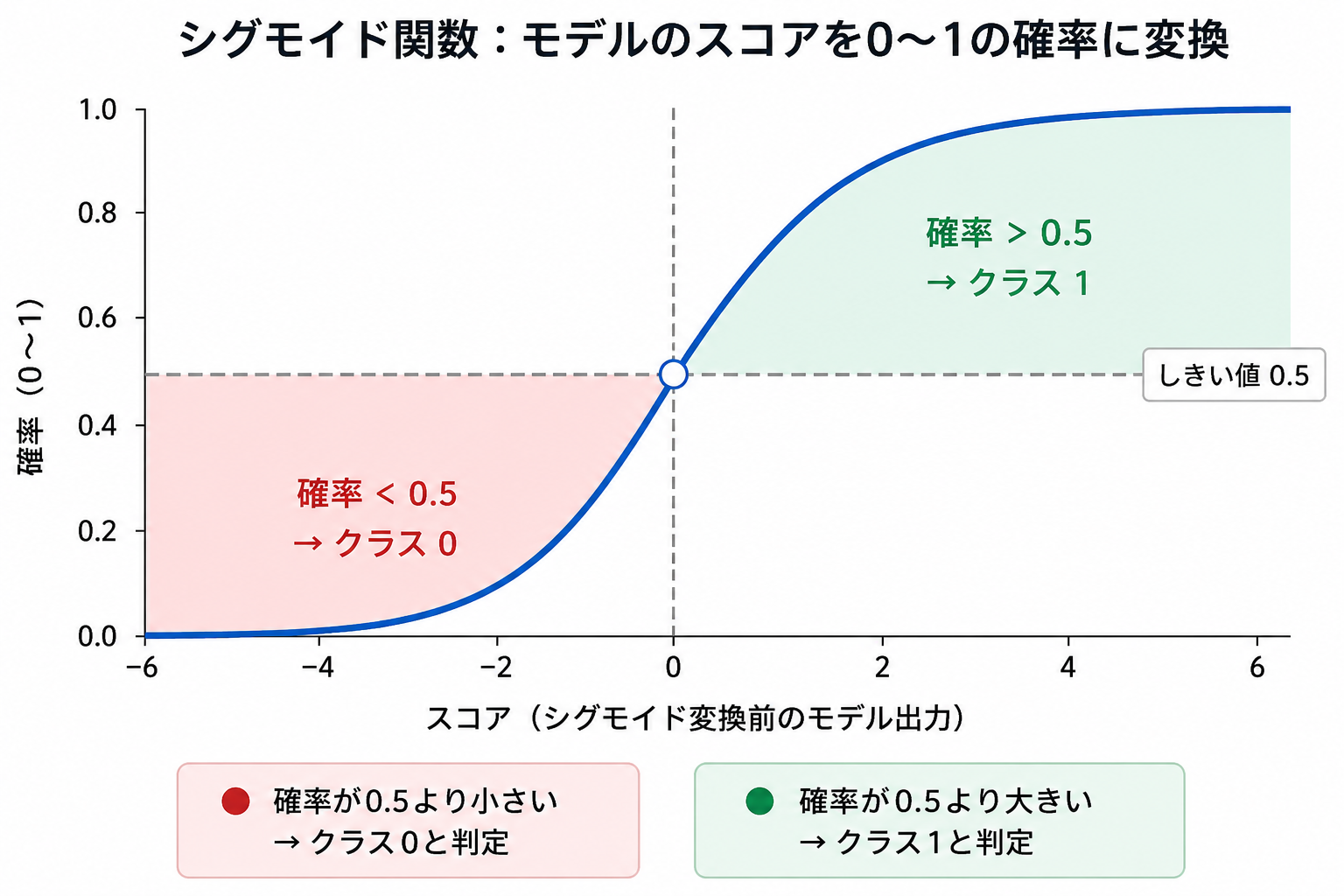
では実際に作りましょう。前回学んだ標準化を前処理に入れます (ロジスティック回帰はスケールを揃えると安定して学習できます)。
💡 正解率(accuracy)とは:
「テストデータのうち、正しく当てられた割合」です。0.982 なら171人中ほぼ全員を正しく分類できた、ということ。
ただし、正解率にはちょっとした落とし穴もあります。それは次の レッスン8 でくわしく扱います。
3. predict_proba — 確率を見る
predict は「0か1か」の区分を返しますが、predict_proba を使うと
その判断の“自信”=確率を見られます。医療では「どれくらい確からしいか」がとても重要です。
🩺 確率で見ることの意味: 患者0は「良性88%」と自信を持って良性と判断しています。一方、もし「良性52% / 悪性48%」のような患者がいたら、 判断はギリギリ。こういう「確信が低いケース」を見つけて、人間が追加で確認する—— 確率を出せることは、医療AIで特に大切な性質です。
4. 練習問題
分類モデルの正解率を出そう
乳がんデータで、標準化 → ロジスティック回帰の流れでモデルを学習し、テストデータの正解率を表示してください。
(分割は test_size=0.3, random_state=42)
ヒントを見る(答え+解説)
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
scaler = StandardScaler().fit(X_train)
# モデルを学習し、テストの正解率を表示してください
model = LogisticRegression(max_iter=5000, random_state=42)
model.fit(scaler.transform(X_train), y_train)
pred = model.predict(scaler.transform(X_test))
print("正解率:", round(accuracy_score(y_test, pred), 3)) # 0.982正解率は 0.982。標準化してからロジスティック回帰にかけることで、安定して高精度に分類できます。
1人目の確率を確認しよう
上のモデルで、テスト1人目(index 0)の 悪性確率・良性確率を predict_proba で表示してください。
ヒントを見る(答え+解説)
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
scaler = StandardScaler().fit(X_train)
model = LogisticRegression(max_iter=5000, random_state=42).fit(scaler.transform(X_train), y_train)
proba = model.predict_proba(scaler.transform(X_test))
# 1人目(index 0)の 悪性確率(列0)・良性確率(列1) を表示してください
print("悪性確率:", round(proba[0][0], 3)) # 0.118
print("良性確率:", round(proba[0][1], 3)) # 0.882悪性0.118・良性0.882。良性の確率が0.5を大きく超えているので、自信を持って「良性(1)」と判断されます。
確率としきい値の関係を確かめよう
1人目について、良性確率が0.5より大きいかと、predictの予測(0か1か)を両方表示し、 「確率0.5超え → クラス1」になっていることを確かめてください。
ヒントを見る(解説)
出力は 良性確率が0.5超え?: True と predictの予測: 1 になります。
良性の確率が0.5を超えたので、予測は「良性(1)」。
このように predict は内部で「確率0.5を境に区分を決めている」だけなのです。
しきい値(0.5)を動かせば、判断の厳しさを調整することもできます。
5. まとめ
このレッスンのポイント
- 分類=区分を当てる問題(回帰は数値)。2択は二値分類
- ロジスティック回帰は名前に「回帰」が付くが分類のモデル
- まず確率で答え、0.5を境に区分を決める(シグモイドで0〜1に変換)
predict=区分(0/1)/predict_proba=確率(自信の度合い)- 正解率(accuracy)=正しく当てた割合(ただし落とし穴あり→次回)
自由に試してみましょう:
完了するとコース一覧に進捗が記録されます