1. 「回帰」=数値を予測する
いよいよ、はじめての機械学習モデルを作ります。最初に取り組むのは 回帰(かいき / regression)。 これは前回までに何度か出てきた言葉で、「数値そのものを予測する問題」のことです。 たとえば「年齢から最高血圧を予測する」「広さから家賃を予測する」など、答えが数値になるものが回帰です。
その中でいちばんシンプルなのが 線形回帰(せんけいかいき / Linear Regression)。 データに1本の直線をできるだけうまく当てはめて、その直線で予測します。 下の図を見てください。青い点が実際のデータ、赤い直線がモデルが学習した「予測の線」です。
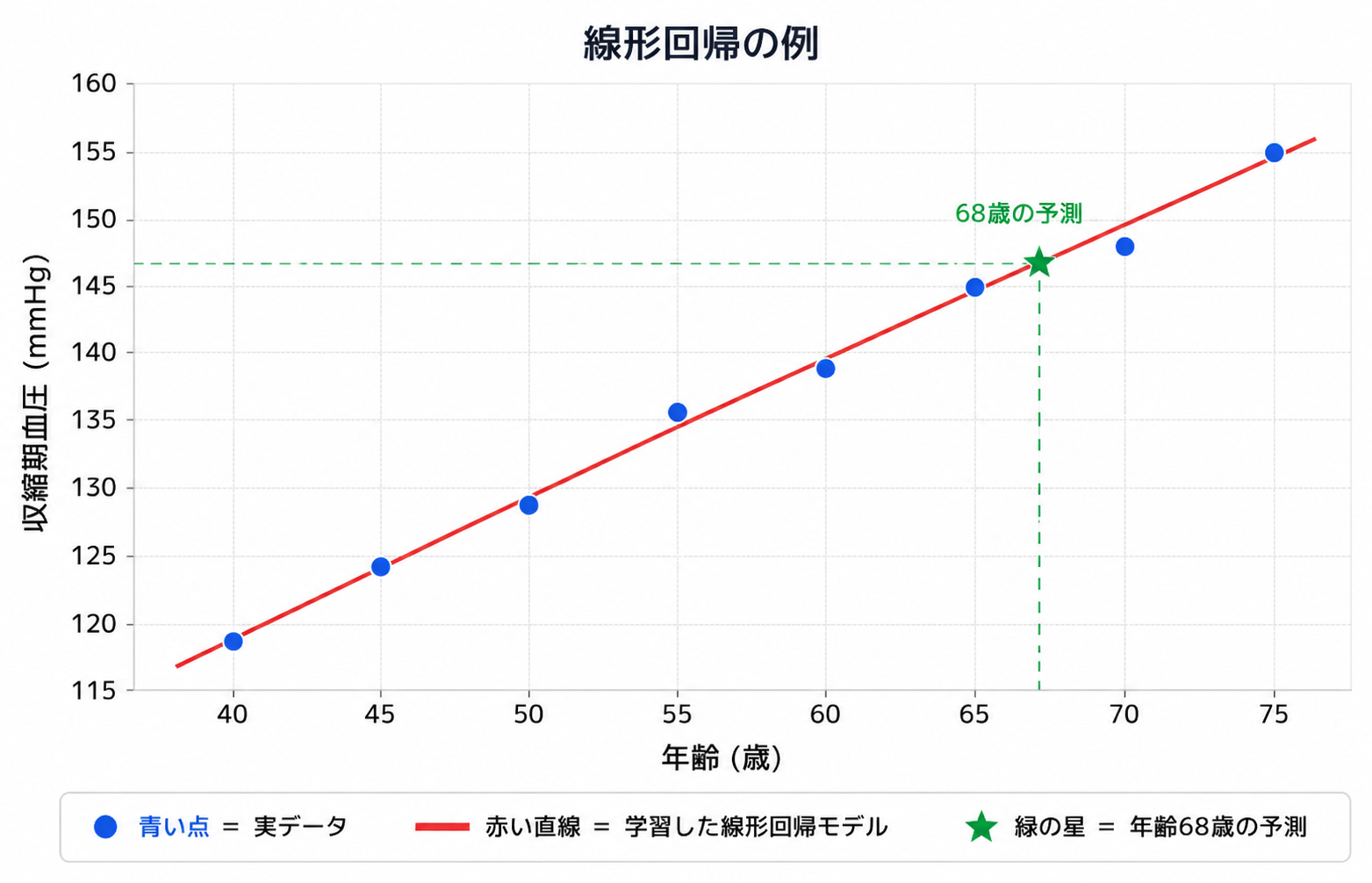
💡 直線の正体は「傾き」と「切片」: 中学で習った直線の式 y = a × x + b を覚えていますか? 線形回帰がやっているのは、まさにこの a(傾き) と b(切片) を、 データに最もよく合うように決めることです。学習(fit)=最適な傾きと切片を見つける作業、と考えてください。
2. モデルを作って学習させる(fit)
では実際に作ってみましょう。手順はたった3つ——① モデルを用意 → ② fit で学習 → ③ 中身を確認です。
「年齢」から「最高血圧(SBP)」を予測するモデルを作ります。
💡 傾き・切片の意味(ここが回帰の読み方):
- 傾き
coef_≈ 1.03 … 年齢が1歳上がるごとに、最高血圧が約1.03 上がるという関係 - 切片
intercept_≈ 77.1 … 直線の高さの基準(年齢が0のときの値。あくまで計算上の基準点)
つまりこのモデルは 「SBP ≒ 1.03 × 年齢 + 77.1」 という直線を見つけた、ということです。
⚠ なぜ age は二重のカッコ [[40], [45], ...] なの?:
scikit-learnは「1人がいくつもの特徴量を持つ」前提で作られているため、特徴量 X は必ず
「行=サンプル、列=特徴量」の2次元の形で渡します。
今回は特徴量が「年齢」1つだけですが、それでも [[40], [45], ...](各行に1個ずつ)という形にする必要があります。
ラベル y は答えが1人1つなので、ふつうのリストでOKです。
3. 予測する(predict)
学習が済んだモデルに、新しい年齢を与えて最高血圧を予測させましょう。使うのは predict です。
予測したいデータも、学習のときと同じ2次元の形で渡します。
🩺 これが機械学習の予測: 学習に使っていない「68歳」のデータでも、モデルは 約147.2 と予測しました。 これは「SBP ≒ 1.03 × 68 + 77.1」を計算した結果です。 データから見つけた関係(直線)を使って、未知の入力にも答えを出す——これがモデルの仕事です。
4. 練習問題
58歳の血圧を予測しよう
下記のモデル(学習済み)を使って、58歳の最高血圧を予測して表示してください。
ヒントを見る(答え+解説)
from sklearn.linear_model import LinearRegression
age = [[40], [45], [50], [55], [60], [65], [70], [75]]
sbp = [118, 124, 128, 135, 138, 145, 148, 155]
model = LinearRegression().fit(age, sbp)
# 58歳の最高血圧を予測して表示してください
print(round(model.predict([[58]])[0], 1)) # 136.9predict([[58]]) で約 136.9。[[58]] と二重カッコにするのを忘れずに。
predict の結果はリスト(配列)で返るので、[0] で最初の値を取り出しています。
自分でモデルを作ってみよう
体重から1回の投薬量を予測するモデルを作ります。下記の weight(体重kg)と dose(投薬量mg)で
モデルを学習させ、体重75kgの人の投薬量を予測してください。
ヒントを見る(答え+解説)
from sklearn.linear_model import LinearRegression
weight = [[50], [60], [70], [80]]
dose = [100, 120, 140, 160]
# モデルを作って学習させ、体重75kgの投薬量を予測してください
model = LinearRegression().fit(weight, dose)
print("傾き:", round(model.coef_[0], 2)) # 2.0
print("75kgの予測:", round(model.predict([[75]])[0], 1)) # 150.0このデータは「投薬量 = 体重 × 2」という関係なので、傾き coef_ はぴったり 2.0。
体重75kgなら 75 × 2 = 150mg と予測されます。きれいな直線関係だと、モデルも素直にその関係を学びます。
傾きの意味を読み取ろう
最初の「年齢→血圧」モデルで、年齢が10歳上がると最高血圧がいくつ上がるかを、
傾き(coef_)から計算して表示してください。(ヒント:傾き × 10)
ヒントを見る(答え+解説)
from sklearn.linear_model import LinearRegression
age = [[40], [45], [50], [55], [60], [65], [70], [75]]
sbp = [118, 124, 128, 135, 138, 145, 148, 155]
model = LinearRegression().fit(age, sbp)
# 年齢が10歳上がると血圧がいくつ上がるか
print(round(model.coef_[0] * 10, 1), "上がる") # 10.3 上がる傾きが約1.03なので、10歳ぶんでは 1.03 × 10 ≈ 10.3。
傾き(coef_)を読むと「特徴量が1増えると答えがどれだけ変わるか」が分かる——これが回帰モデルの大きな利点です。
5. まとめ
このレッスンのポイント
- 回帰=数値を予測する問題。線形回帰はデータに直線を当てはめる方法
- 手順は ①
LinearRegression()→ ②.fit(X, y)→ ③.predict(新X) - 特徴量
Xは2次元の形(行=サンプル、列=特徴量)で渡す coef_=傾き(特徴量が1増えると答えがどれだけ変わるか)/intercept_=切片- このモデルは「SBP ≒ 1.03 × 年齢 + 77.1」を学習した
自由に試してみましょう:
完了するとコース一覧に進捗が記録されます