1. モデルの「良し悪し」をどう測る?
前回、年齢から血圧を予測するモデルを作りました。では、その予測はどれくらい当たっているのでしょうか? 機械学習では、予測値と実際の値(実測値)の「ズレ」を数値で測ってモデルを評価します。 このズレのことを 誤差(ごさ / error) と呼びます。
下の図は、テストデータでの「予測値 vs 実測値」です。点が斜めの点線(=完全な予測)に近いほど、良いモデルです。 点線から離れている点が多いほど、予測が外れているということです。
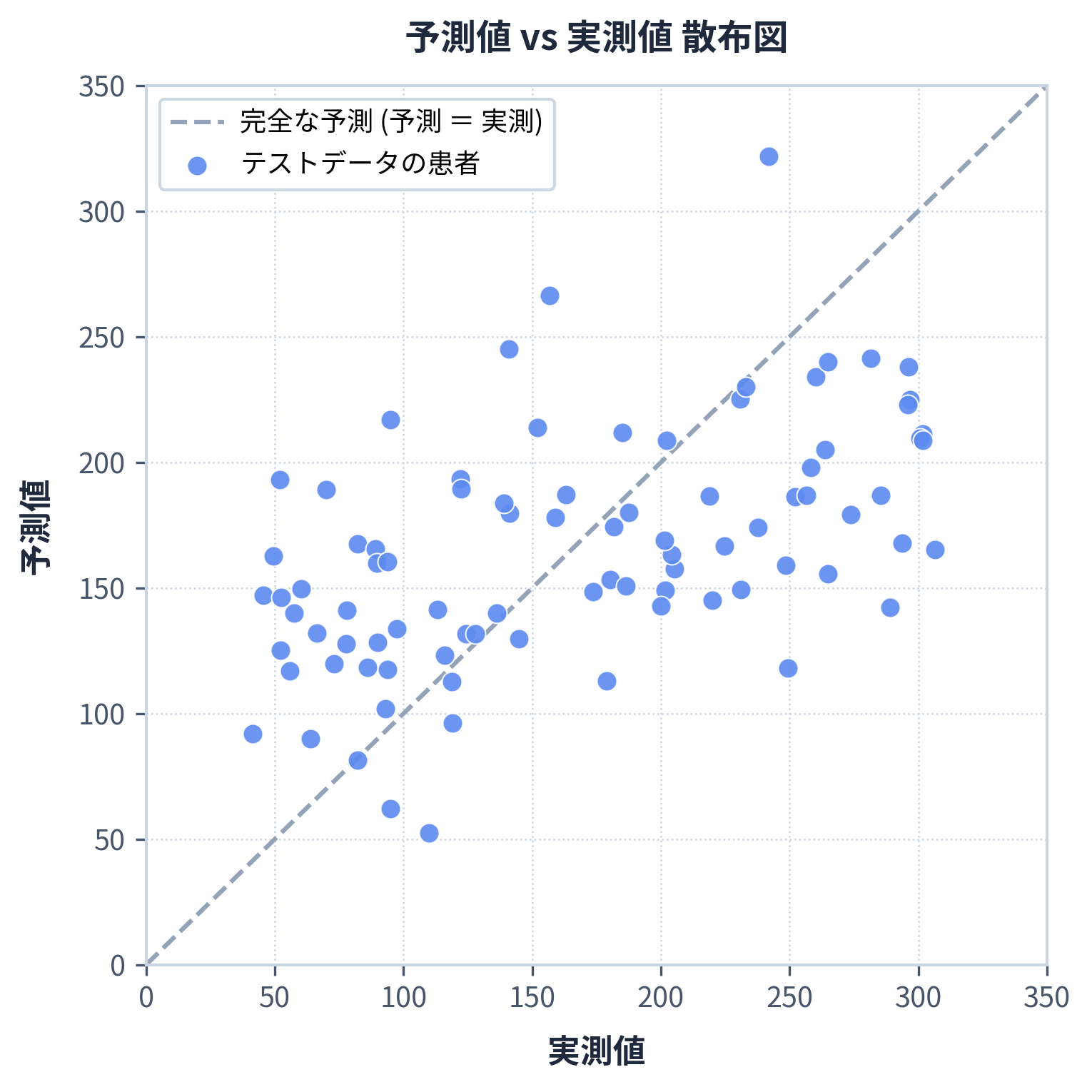
💡 「ものさし」が必要: 図を見れば「だいたい合ってる/外れてる」は分かりますが、2つのモデルを比べるには数値の「ものさし(評価指標)」が要ります。 回帰では、よく使う指標が MAE・MSE・RMSE・R² の4つ。順に見ていきましょう。
2. 3つの誤差の指標(MAE・MSE・RMSE)
まずは「平均どれくらいズレているか」を測る3つの指標です。どれも小さいほど良い(誤差が少ない)と覚えてください。
| 指標 | 意味 | 特徴 |
|---|---|---|
| MAE(平均絶対誤差) | 誤差の絶対値の平均 | いちばん直感的。「平均◯ズレる」 |
| MSE(平均二乗誤差) | 誤差を2乗して平均 | 大きな外れに敏感(2乗で強調) |
| RMSE | MSEの平方根(√) | 単位が元に戻り読みやすい |
実際に、糖尿病データ(BMIから進行度を予測)で測ってみましょう。 「分割 → 学習 → 予測 → 評価」というこれまでの流れを通しで行います。
💡 読み方:
MAE 52.3 は「予測が平均で約52ズレる」という意味(進行度の単位で)。
RMSE 63.7 は MAE より少し大きいですね。これはRMSEが大きな外れを強く反映するためです。
MAEとRMSEはどちらも「平均的な誤差の大きさ」を表しますが、大外しを重く見たいときはRMSEを使います。
3. R²(決定係数)— どれだけ説明できたか
MAEやRMSEは「単位つきの誤差」なので、データが変わると大小の感覚がつかみにくいことがあります。 そこで便利なのが R²(アールにじょう / 決定係数)。 これは「モデルがデータのばらつきを、どれだけ説明できたか」を 0〜1 で表す指標です。
📏 R² の目安:
- 1.0 に近い…とても良い(ほぼ完璧に説明できている)
- 0 くらい…「いつも平均値を答える」のと同じ程度(ほぼ役立たず)
- マイナス…平均を答えるより悪い(モデルが不適切)
🩺 R²=0.233 は低い。なぜ?: このモデルは「BMI」というたった1つの特徴量だけで進行度を予測しています。 病気の進行には血圧・血糖値など多くの要因が関わるので、1項目だけでは説明しきれず R² が低いのです。 次の レッスン6 で、複数の特徴量を使うと R² が上がるのを確かめます。
4. 練習問題
MAEを計算しよう
下記の実測値と予測値から、mean_absolute_error で MAE を計算して表示してください。
ヒントを見る(答え+解説)
from sklearn.metrics import mean_absolute_error
actual = [100, 150, 200, 120]
pred = [110, 140, 190, 130]
# MAE を計算して表示してください
print("MAE:", mean_absolute_error(actual, pred)) # 10.0各誤差は +10, -10, -10, +10。絶対値はすべて10なので、平均(MAE)は 10.0。
「平均して10ズレている」という意味です。
MSEとRMSEを計算しよう
問題1と同じデータで、mean_squared_error で MSE を求め、その平方根(** 0.5)で RMSE も表示してください。
ヒントを見る(答え+解説)
from sklearn.metrics import mean_squared_error
actual = [100, 150, 200, 120]
pred = [110, 140, 190, 130]
# MSE と RMSE を表示してください
mse = mean_squared_error(actual, pred)
print("MSE:", mse) # 100.0
print("RMSE:", mse ** 0.5) # 10.0誤差はすべて±10。2乗するとすべて100なので MSE は 100.0、その平方根 RMSE は 10.0。
今回は誤差が一定なので MAE と RMSE が同じ値になりますが、ばらつきが大きいほど RMSE は MAE より大きくなります。
R²で評価しよう
糖尿病データ(BMIの1項目)でモデルを作り、テストデータでの R² を計算して表示してください。
(分割は test_size=0.2, random_state=42)
ヒントを見る(答え+解説)
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
d = load_diabetes()
X = d.data[:, [2]]
y = d.target
# 分割 → 学習 → 予測 → R² を表示してください
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42)
model = LinearRegression().fit(X_train, y_train)
pred = model.predict(X_test)
print("R²:", round(r2_score(y_test, pred), 3)) # 0.233R² は 0.233。「BMIだけでは進行度の約23%しか説明できていない」という意味です。
特徴量を増やせばこの数字は改善できます(次のレッスン)。
5. まとめ
このレッスンのポイント
- モデルの評価は「予測と実測のズレ(誤差)」を測る
- MAE=誤差の絶対値の平均(直感的)/MSE=誤差の2乗の平均(大外しに敏感)
- RMSE=MSEの平方根(単位が戻り読みやすい)。MAE・MSE・RMSEは小さいほど良い
- R²=説明できた割合(0〜1)。1に近いほど良い、0は平均並み
- 評価は必ずテストデータで行う(分割→学習→予測→評価)
自由に試してみましょう:
完了するとコース一覧に進捗が記録されます