1. 機械学習の「登場人物」を覚えよう
前回、機械学習は「データからパターンを学ぶ」ことだと学びました。 ここからは少しずつ言葉を覚えていきます。とはいえ難しくありません。 機械学習の主な登場人物は3つだけです。
📖 まず覚える3つの言葉:
- 特徴量(feature)…予測の手がかりになる数値。検査値や年齢など。慣習で
X(大文字)と書く - ラベル(label)/ターゲット(target)…予測したい「答え」。正解データとも呼ぶ。慣習で
y(小文字)と書く - モデル(model)…特徴量
Xから答えyを予測する“仕組み”。学習することで賢くなる
前回の乳がんデータでいえば、30項目の検査値が「特徴量 X」、 「悪性/良性」が「ラベル y」です。実際にコードで分けてみましょう。
💡 「サンプル」という言葉:
データ1件(ここでは患者1人分)のことを サンプル(sample) と呼びます。
X[0] は1人目のサンプルの特徴量(30個の数値)、y[0] はその人の答え(悪性か良性か)です。
「たくさんのサンプル(X, y)を見せて、モデルにパターンを学ばせる」——これが機械学習の基本動作です。
2. 学習(fit)と推論(predict)の2ステップ
モデルを使うときの流れは、大きく2ステップです。下の図がこのコース全体の地図になります。
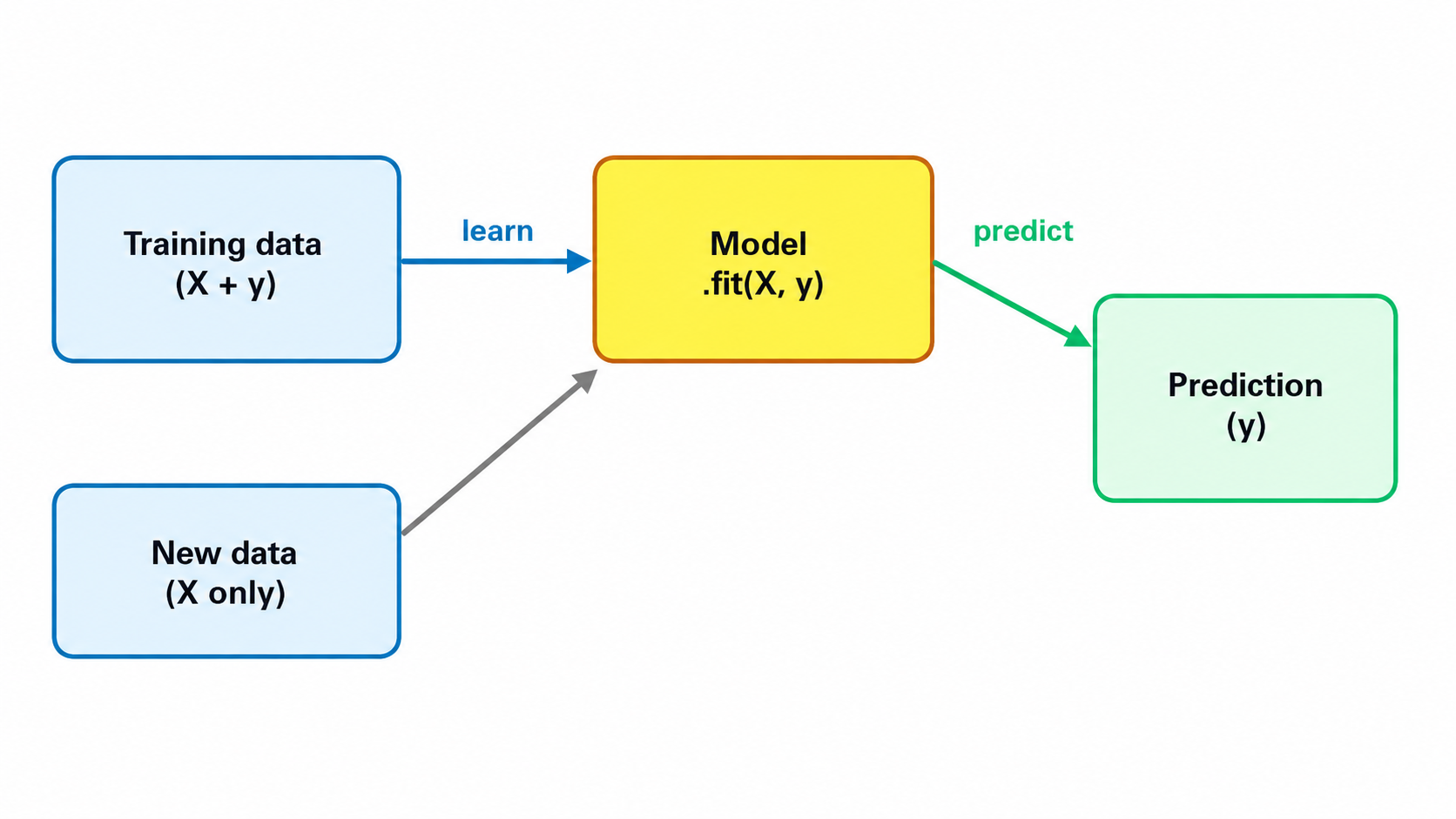
- ① 学習(fit)…答えつきのデータ(X と y)を見せて、モデルを賢くするステップ。 「訓練(トレーニング)」とも呼びます。人が問題集を答え合わせしながら解いて覚えるイメージです。
- ② 推論(predict)…学習済みモデルに、新しいデータ(X)を与えて答えを出させるステップ。 「予測」とも呼びます。本番のテストを解くイメージです。
実際のコードは、毎回ほぼ同じ形になります(今は「こういう形なんだ」と眺めるだけでOK)。
# ① 学習(fit):答えつきデータでモデルを賢くする
model.fit(X_train, y_train)
# ② 推論(predict):新しいデータに答えを予測させる
predictions = model.predict(X_new)💡 X_train って何?:
上のコードで X_train とあるのは「学習に使うデータ」=訓練データのことです。
実は、手元のデータをすべて学習に使うのではなく、一部を“本番テスト用”に取っておくのが鉄則です。
この「訓練データとテストデータに分ける」話は、次の レッスン3「訓練データとテストデータ」 でくわしく扱います。
実際に model を作って fit / predict するのは レッスン4 からです。
3. データを「特徴量」と「ラベル」の表で見る
特徴量とラベルを、使い慣れた pandasの表で見てみましょう
(pandasコースで学んだ DataFrame をそのまま使えます)。
「特徴量=表の各列」「ラベル=答えの1列」という対応がはっきりします。
🩺 医療データ文脈: この表のように、医療データは「1行=1人の患者」「各列=検査項目(特徴量)」「答えの列=診断(ラベル)」という形になります。 pandasで整えたデータを、そのまま機械学習モデルに渡せる——だからこのコースは pandas の知識が前提なのです。
4. 練習問題
データを X と y に分けよう
load_diabetes(糖尿病データ)を読み込み、特徴量 X と ラベル y に分けて、それぞれの shape を表示してください。
ヒントを見る(答え+解説)
from sklearn.datasets import load_diabetes
data = load_diabetes()
# X(特徴量)と y(ラベル)に分けて、それぞれの shape を表示してください
X = data.data
y = data.target
print("X の形:", X.shape) # (442, 10)
print("y の形:", y.shape) # (442,)data.data が特徴量 X、data.target がラベル y です。442人 × 10項目の特徴量と、442人分の答えがあります。どのデータセットでもこの形(X と y)は共通です。
1人分(サンプル)を取り出そう
糖尿病データの1人目の特徴量の個数(len(X[0]))と、その人の答え(y[0])を表示してください。
ヒントを見る(答え+解説)
from sklearn.datasets import load_diabetes
data = load_diabetes()
X = data.data
y = data.target
# 1人目の特徴量の個数 と、その人の答え(y[0]) を表示してください
print("特徴量の数:", len(X[0])) # 10
print("1人目の答え:", y[0]) # 151.01人目のサンプルは10個の特徴量を持ち、その答えは 151.0(数値)。答えが数値なので、これは回帰の問題です(数値を予測)。
ラベルの内訳を数えよう
乳がんデータで、良性(y が 1)と悪性(y が 0)がそれぞれ何人いるかを数えて表示してください。
(ヒント:(y == 1).sum() で1の個数を数えられます)
ヒントを見る(答え+解説)
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer()
y = data.target
# 良性(1)と悪性(0)がそれぞれ何人か数えて表示してください
print("良性(1):", (y == 1).sum(), "人") # 357
print("悪性(0):", (y == 0).sum(), "人") # 212良性357人・悪性212人。このようにクラス(区分)ごとの人数のバランスを最初に確認するのは大切です。 片方に極端に偏っていると、モデルの評価に注意が必要になります(くわしくはレッスン8で扱います)。
5. まとめ
このレッスンのポイント
- 特徴量(X)=予測の手がかりの数値/ラベル(y)=予測したい答え
- モデル=Xからyを予測する仕組み。サンプル=データ1件
- 機械学習は ① 学習(fit)→ ② 推論(predict) の2ステップ
data.data=X、data.target=y で取り出せる- pandasの表で見ると「列=特徴量」「答えの列=ラベル」が一目で分かる
自由に試してみましょう:
完了するとコース一覧に進捗が記録されます