1. AIってなんだろう?
「AI」という言葉は、いまや毎日のように耳にします。でも改めて 「AIって結局なに?」と聞かれると、説明が難しいかもしれません。 このコースは、AI・機械学習の知識がゼロでも大丈夫。まずは身近な例から、ゆっくり始めましょう。
実はあなたは、毎日たくさんのAIに触れています。
- スマホの顔認証(あなたの顔を見分ける)
- 動画サイトのおすすめ表示(好みに合いそうな動画を選ぶ)
- 音声アシスタント(話しかけた言葉を聞き取る)
- 自動翻訳・迷惑メールの自動振り分け
- 医療現場の画像診断支援(レントゲンやCTから異常を見つける手助け)
これらに共通するのは、「これまで人間がやっていた“判断”を、コンピュータが代わりに行っている」こと。 このように、人間の知的な作業をコンピュータに行わせる技術を、ざっくり AI(人工知能) と呼びます。
⚠ 初回の読み込みについて: このコースのコードは scikit-learn(機械学習のライブラリ)を使います。pandasよりさらに大きいため、 各ページで最初にコードを実行するとき、読み込みに十数秒〜数十秒かかることがあります(2回目以降は速くなります)。 画面上部のバーが消えたら準備完了の合図です。
2. AI・機械学習・ディープラーニングの関係
ニュースでは「AI」「機械学習」「ディープラーニング」「生成AI」といった言葉が、ほぼ同じ意味のように使われます。 でも、これらは「入れ子(マトリョーシカ)」の関係になっています。
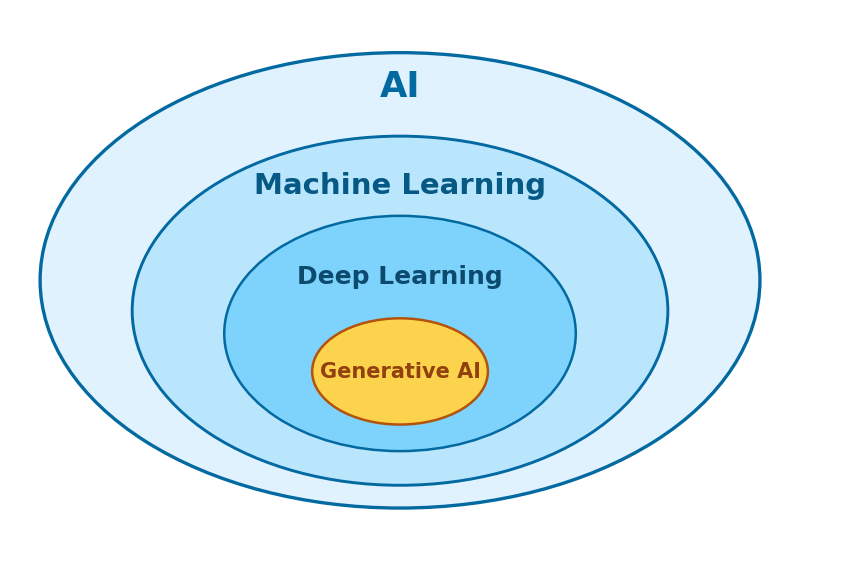
- AI(人工知能)…いちばん広い言葉。「賢く振る舞うコンピュータ」全般を指す
- 機械学習…AIを実現する代表的な方法。データからパターンを学ぶ(このコースの主役)
- ディープラーニング…機械学習の一種で、「ニューラルネットワーク」という仕組みを使う特に強力な方法
- 生成AI…ディープラーニングの応用。文章や画像を“生成”する(ChatGPTなど)
💡 まずはここだけ: 「機械学習はAIの中心的な手段」とだけ覚えればOKです。 このコースで学ぶのは、その機械学習。ディープラーニングや生成AIは、機械学習を理解した先にある発展分野です (本格的にはE資格対策コース・医療AIコースで扱います)。
3. 「ルールを書く」から「データから学ぶ」へ
では、機械学習は今までのプログラムと何が違うのでしょうか。 「迷惑メールを見分けるプログラム」を例に考えてみます。
従来のやり方(ルールベース)では、人間がルールを1つずつ書きます。 「“当選”という単語が入っていたら迷惑メール」「URLが10個以上あったら迷惑メール」…。 でも、迷惑メールの手口は次々に変わるので、ルールを書き続けるのは大変です。
機械学習では、考え方が逆転します。ルールを人が書く代わりに、 「迷惑メールの例」と「普通のメールの例」を大量に見せて、コンピュータ自身にパターンを見つけさせるのです。
| ルールベース(従来) | 機械学習 | |
|---|---|---|
| 誰がルールを作る | 人間が1つずつ書く | データから自動で学ぶ |
| 必要なもの | 細かいルールの知識 | たくさんの例(データ) |
| 変化への強さ | 都度ルールを書き直す | 新しいデータで学び直せる |
| 得意なこと | 条件がはっきりした作業 | パターンが複雑な作業(画像・言葉など) |
🩺 医療データ文脈: 「検査値がいくつ以上なら病気」と単純なルールで割り切れない場面はたくさんあります。 複数の検査項目が複雑に絡み合うようなとき、過去の大量のデータからパターンを学ぶ機械学習が力を発揮します。
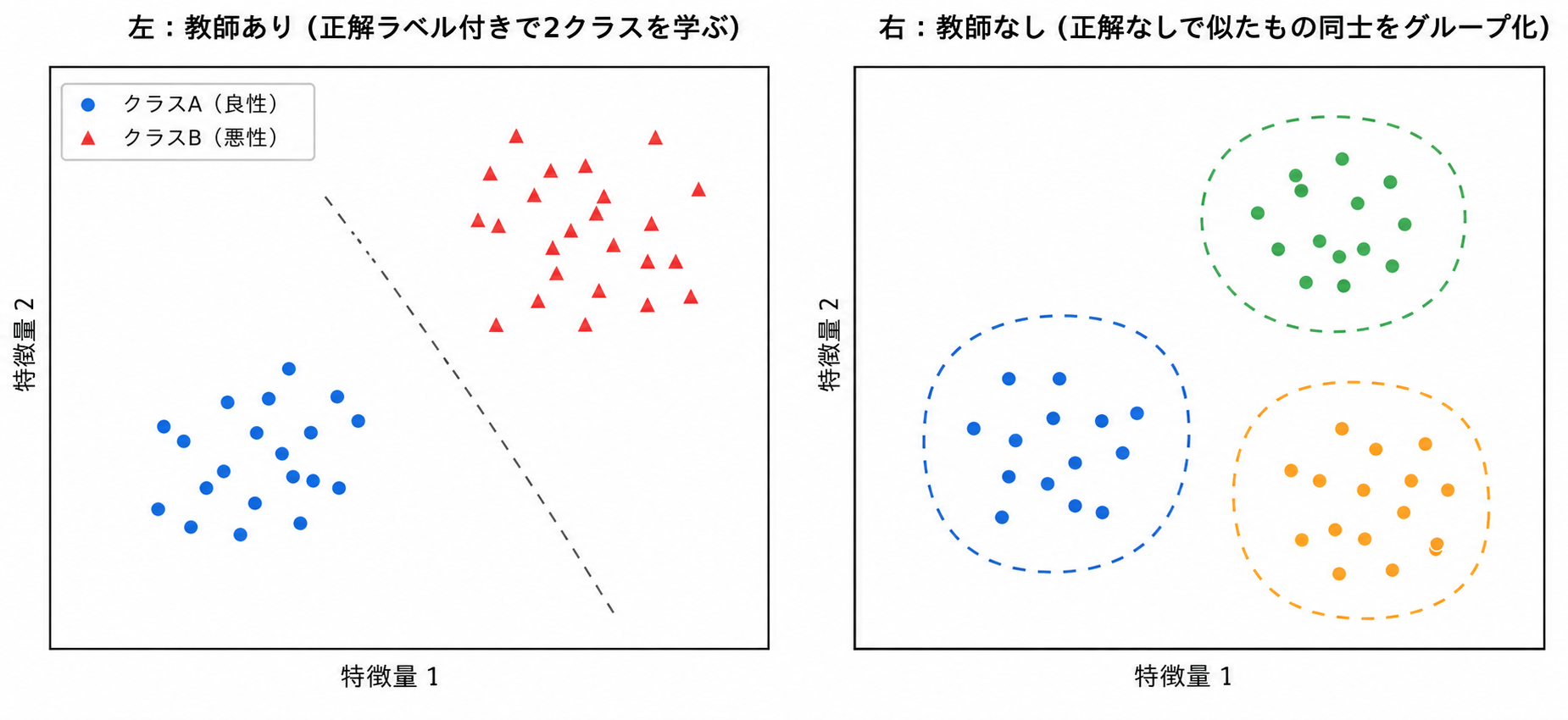
4. 機械学習の3つの種類
機械学習は、「何をヒントに学ぶか」で大きく3種類に分かれます。
- 教師あり学習…正解つきのデータで学ぶ。例:「この検査データ=悪性」という答えを大量に見せて、新しい患者が悪性か良性かを予測させる
- 教師なし学習…正解なしのデータからグループや構造を見つける。例:似た特徴の患者を自動でグループ分けする
- 強化学習…試行錯誤で、うまくいけば報酬を与えて上達させる。例:ゲームAIやロボットの制御
🗺 このコースで学ぶ範囲:
- 教師あり学習(回帰・分類)… Unit 2・3 でしっかり(メイン)
- 教師なし学習(クラスタリング)… Unit 4 で体験
- 強化学習… 考え方の紹介のみ(本コースでは深入りしない)
まずは「正解つきで学ぶ=教師あり」「正解なしでグループ分け=教師なし」の2つを押さえれば十分です。
5. scikit-learnにさわってみる
このコースで使う機械学習ライブラリが scikit-learn(サイキット・ラーン) です。 細かい使い方は次回以降。まずは「動く」ことを体験しましょう。 scikit-learnには練習用の医療データが最初から入っていて、追加のダウンロードなしで使えます。
💡 いま動かしたデータの意味: このデータは 569人分の検査結果で、1人につき 30項目の数値(細胞核の大きさなど)が入っています。 この30項目が「手がかり=特徴量」、予測したい「悪性/良性」が「答え=ラベル」です。 特徴量から答えを当てる——これが、次回から作っていく機械学習モデルの正体です。
6. 練習問題
各セルのコードを書き換えて「▶ 実行」を押してみましょう。「↺ リセット」で元に戻せます。
乳がんデータの大きさと区分を見てみよう
load_breast_cancer を読み込み、データの大きさ(shape)と予測したい区分(target_names)を表示してください。
ヒントを見る(答え+解説)
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer()
# データの大きさ(shape)と、予測したい区分(target_names)を表示してください
print("大きさ:", data.data.shape) # (569, 30)
print("区分:", list(data.target_names)) # ['malignant', 'benign']569人 × 30項目のデータで、予測する区分は「malignant(悪性)」「benign(良性)」の2つ。正解(区分)が用意されている=教師あり学習のデータです。
糖尿病データ(回帰用)をのぞいてみよう
load_diabetes(糖尿病の進行度データ)を読み込み、データの大きさと、答え(target)の最初の5件を表示してください。
ヒントを見る(答え+解説)
from sklearn.datasets import load_diabetes
data = load_diabetes()
# データの大きさと、target の最初の5件を表示してください
print("大きさ:", data.data.shape) # (442, 10)
print("答えの例:", list(data.target[:5])) # [151.0, 75.0, 141.0, 206.0, 135.0]こちらの答え(target)は「悪性/良性」のような区分ではなく、数値(連続値)です。 このように数値そのものを予測する問題を「回帰」と呼びます(Unit 2で扱います)。 答えが「区分」なら分類、「数値」なら回帰、と区別できます。
「特徴量」の中身を見てみよう
乳がんデータの 特徴量名の最初の5個(feature_names[:5])を表示して、「手がかり」が具体的に何かを確かめてください。
ヒントを見る(答え+解説)
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer()
# 特徴量名の最初の5個を表示してください
print(list(data.feature_names[:5]))
# ['mean radius', 'mean texture', 'mean perimeter', 'mean area', 'mean smoothness']「半径(radius)」「きめ(texture)」「周囲長(perimeter)」「面積(area)」など、細胞核を測った数値が並びます。 こうした1項目1項目が「特徴量=予測の手がかり」。機械学習は、この30個の手がかりを総合して「悪性か良性か」を予測します。
7. まとめ
このレッスンのポイント
- AI ⊃ 機械学習 ⊃ ディープラーニング(生成AIはその中の応用)。機械学習はAIの中心的な手段
- 機械学習は「人がルールを書く」のではなく 「データからパターンを学ぶ」
- 3種類:教師あり(正解つき)・教師なし(正解なし)・強化(試行錯誤)
- データは 特徴量(手がかり)+ ラベル(答え) でできている
- 答えが「区分」なら分類、「数値」なら回帰
- scikit-learn には練習用の医療データが同梱(DL不要で動かせる)
自由に試してみましょう:
完了するとコース一覧に進捗が記録されます