セマンティックセグメンテーション
- 0.概要
- 1.FCN, U-Net
- キーワードまとめ
Contents
0.章の概要
セグメンテーションとは、画像や動画を複数の領域に分割し、それぞれの領域にラベルを付ける技術です。その中の1つである
以下では、セマンティックセグメンテーションの代表的なモデル解説から、その応用にかけてわかりやすく解説していきます。
1. FCN, U-Net
学習キーワード: スキップコネクション、アップサンプリング、インスタンスセグメンテーション、パノプティックセグメンテーション(Panoptic Segmentation)
概要(セマンティックセグメンテーションとは)
セマンティックセグメンテーション(Semantic Segmentation)は、画像内の各ピクセルを意味的に分類する技術のことを指し、例えば、道路、建物、車、人といったカテゴリごとに、ピクセル単位でラベルを付け、「画像全体を、意味のある領域に細分化すること」をゴールとしています。(出力ユニット数は、画像サイズ×分類クラス数)
ここでは、その中でも代表的なモデルである、FCN(Fully Convolutional Network)やU-Netについて解説していきます。
FCN(Fully Convolutional Network)
FCNは、セマンティックセグメンテーションを可能にした、初のend-to-endの畳み込みネットワークです。従来の画像分類モデル(VGGやAlexNet)を基盤とし、全結合層をGlobal Average Poolingと1×1 Convolutionに置き換えたことで、畳み込み層とプーリング層のみで構成されるアーキテクチャであることが特徴です。また、これらの改良により、入力画像のサイズに制限を受けることなく、セマンティックセグメンテーションを実行できます。
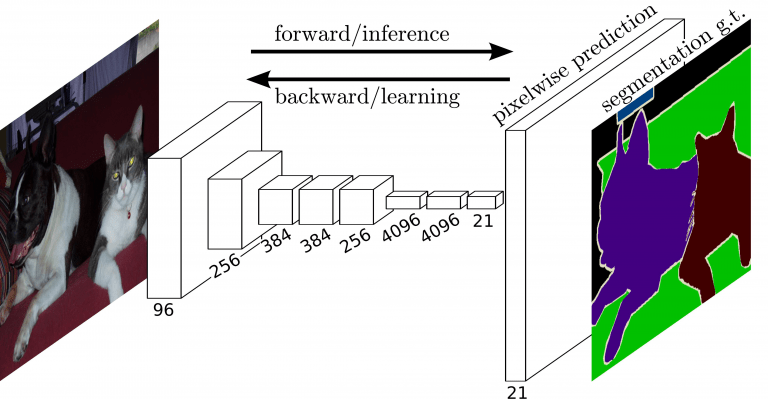
出典: Long, J., Shelhamer, E., & Darrell, T. (2016). Fully Convolutional Networks for Semantic Segmentation.
arXiv preprint arXiv:1605.06211.
https://arxiv.org/abs/1605.06211 本図は教育目的で引用しています。
ヒートマップ
ヒートマップは、画像内の各ピクセルの重要度を可視化するための手法です。全結合層を畳み込みに置き換えたことで、クラス分類が二次元の結果として出力可能になりました。
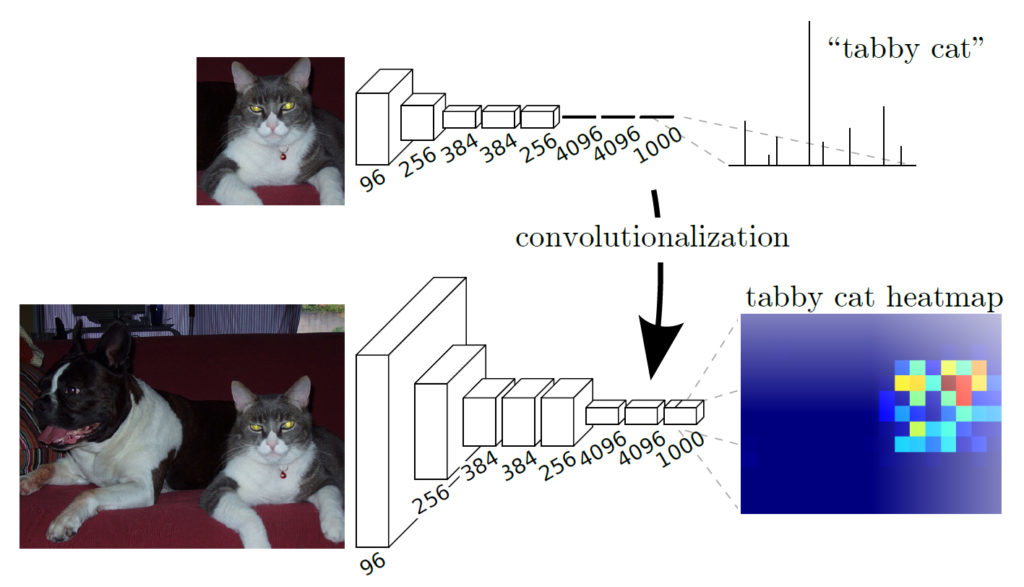
出典: Long, J., Shelhamer, E., & Darrell, T. (2016). Fully Convolutional Networks for Semantic Segmentation.
arXiv preprint arXiv:1605.06211.
https://arxiv.org/abs/1605.06211 本図は教育目的で引用しています。
アップサンプリング
FCNでは、Pooling処理で小さくなったヒートマップを、逆畳込みすることで高解像マップにしていきます。
逆畳み込みは入力データを拡大してから畳み込みを行う処理の事を指し、その手順は以下の通りです。
- strideから1を引いた値分だけ、入力データのピクセル間に0を追加する。
- カーネルサイズから1引いた分だけ特徴マップの周囲に0を配置する。
- paddingで指定されたpixel数だけ周囲の0を削る。
- 畳み込み処理を行う。(必ずstrideは1とする)
例として、入力データ(2×2)、カーネルサイズ(2×2)、stride=2, padding=0の場合の逆畳み込みの手順を下図で示します。

スキップコネクション
アップサンプリングを行うと、物体の境界がぼけてしまうため、FCNではスキップコネクションを導入しています。具体的には、アップサンプリング前の浅い層(高解像度の特徴マップ)の情報を組み合わせる(チャンネルごとに足し算する)ことで、空間的な詳細情報(エッジや境界線など)を保持できます。
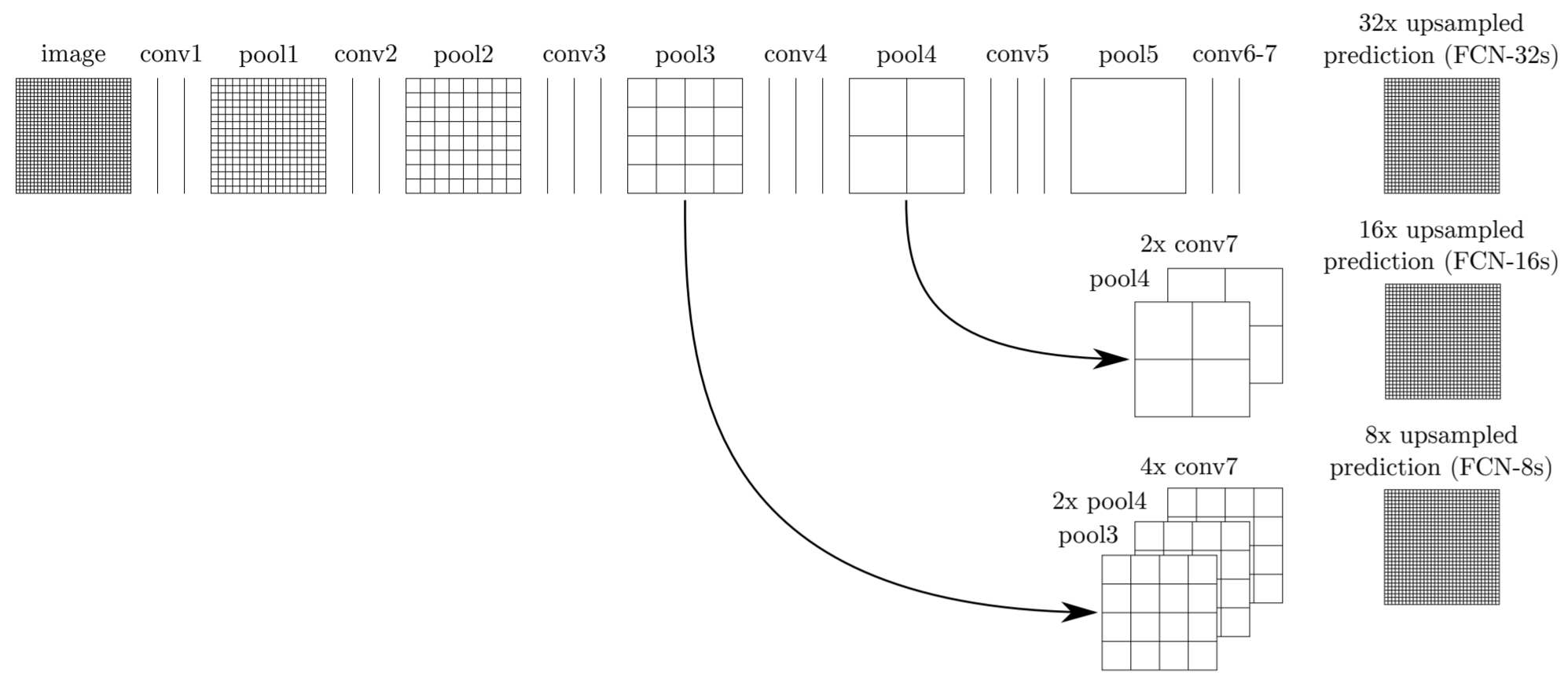
出典: Long, J., Shelhamer, E., & Darrell, T. (2016). Fully Convolutional Networks for Semantic Segmentation.
arXiv preprint arXiv:1605.06211.
https://arxiv.org/abs/1605.06211 本図は教育目的で引用しています。
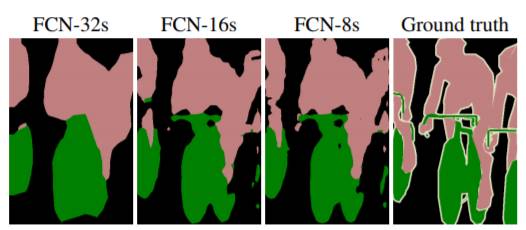
出典: Long, J., Shelhamer, E., & Darrell, T. (2016). Fully Convolutional Networks for Semantic Segmentation.
arXiv preprint arXiv:1605.06211.
https://arxiv.org/abs/1605.06211 本図は教育目的で引用しています。
U-Net
U-Netは、特に医療画像解析向けに設計されたセマンティックセグメンテーションモデルで、FCNを改良したものです。学習画像が少なくてもセグメンテーションの精度が良いと言われています。
下図のように、U字型のネットワーク構造からその名前が付けられています。
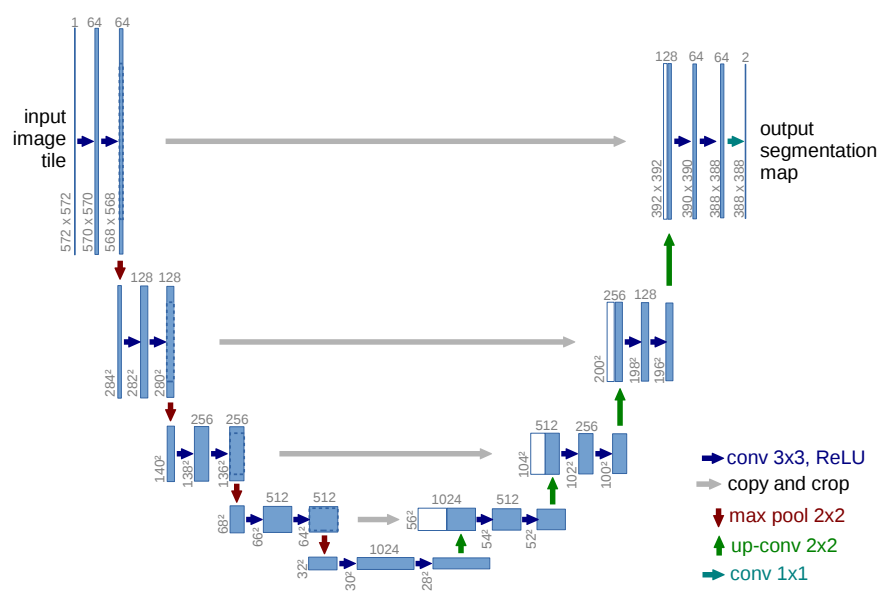
出典: Ronneberger, O., Fischer, P., & Brox, T. (2015). U-Net: Convolutional Networks for Biomedical Image Segmentation.
arXiv preprint arXiv:1505.04597.
https://arxiv.org/abs/1505.04597 本図は教育目的で引用しています。
技術の特徴:
- エンコーダ: エンコーダは、画像の特徴を抽出しつつ、圧縮する役割を果たします。(ResNetなどの既存モデルの構造をほぼそのまま活用可)
-
デコーダ:
デコーダでは、エンコーダで抽出された特徴を貰い、逆畳み込み(deconvolution)で入力画像と同じサイズの確率マップを出力します。
U-Netでは、各階層において、エンコーダの特徴マップをデコーダの特徴マップに連結(スキップコネクション)させており、アップサンプリッグ時に物体の位置情報を捉えやすくなりました。
※抽象化された特徴(U-Netの最下部)から、画像を復元するのではなく、抽象化前の高解像な特徴も使用したすることで効率アップを図っています。
FCNとの違い:
- FCNでもスキップコネクションを使用しますが、特定の浅い層からの情報を限定的に統合するだけです。一方、U-Netは全層にわたってスキップコネクションを行い、情報の損失を最小化します。
セマンティックセグメンテーションと応用技術
ここでは、セマンティックセグメンテーションの応用技術を紹介したいと思います。
まず、ある町中の画像と、セマンティックセグメンテーションで処理をした画像を下記に示しますが、このように、物体が重なっている場合にそれぞれの物体を個別に識別できない欠点があります。


出典: Kirillov, A., He, K., Girshick, R., Rother, C., & Dollár, P. (2018). Panoptic Segmentation.
arXiv preprint arXiv:1801.00868.
https://arxiv.org/abs/1801.00868 本図は教育目的で引用しています。
インスタンスセグメンテーション
インスタンスセグメンテーションは、セマンティックセグメンテーションの進化形で、同じクラスの異なる物体を区別する技術です。例えば、画像に写っている2人の人間を、それぞれ別のインスタンスとして識別することができます。代表的なモデルとしてMask R-CNNがあります。(Mask R-CNNの解説はこちらから)
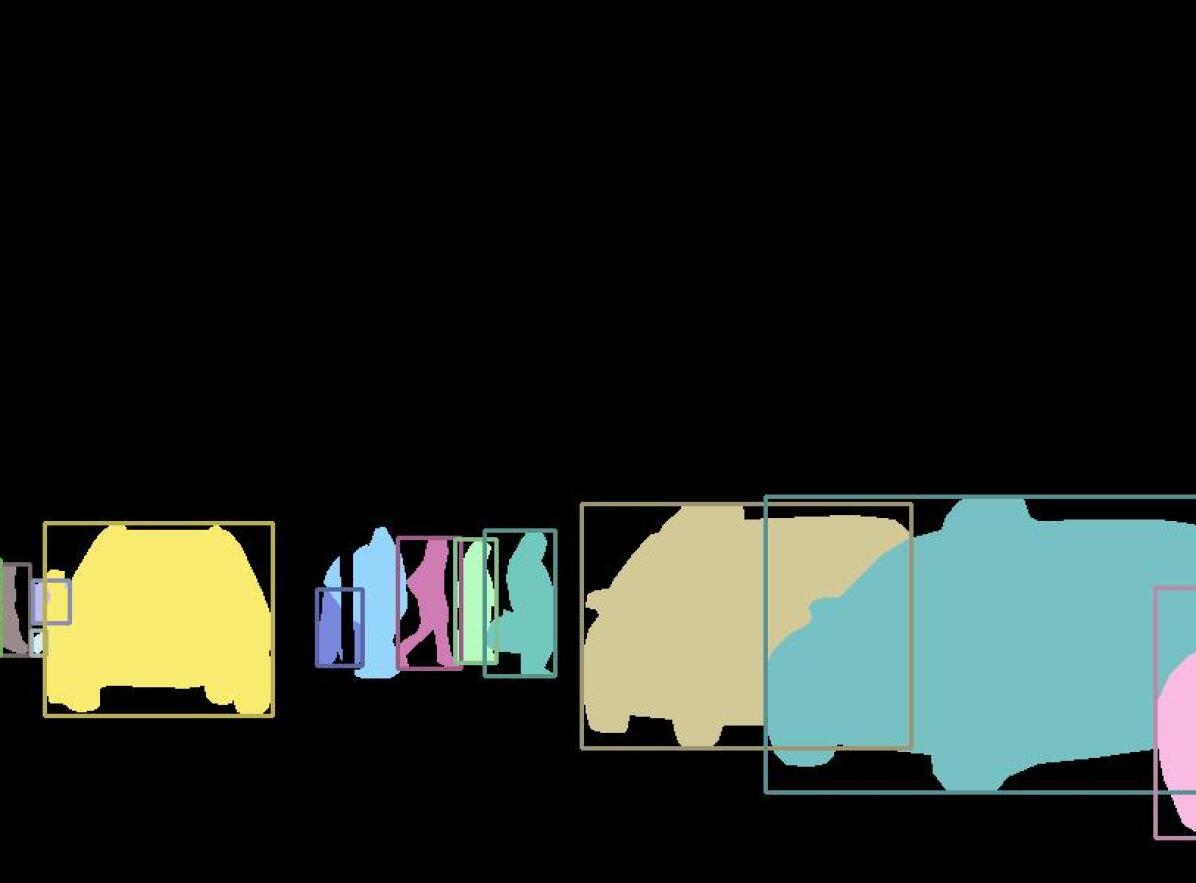
出典: Kirillov, A., He, K., Girshick, R., Rother, C., & Dollár, P. (2018). Panoptic Segmentation.
arXiv preprint arXiv:1801.00868.
https://arxiv.org/abs/1801.00868 本図は教育目的で引用しています。
パノプティックセグメンテーション(Panoptic Segmentation)
パノプティックセグメンテーションは、セマンティックセグメンテーションとインスタンスセグメンテーションを統合したタスクです。背景(例:空や道路)はセマンティックセグメンテーションで分類し、個々の物体(例:車、人)はインスタンスセグメンテーションで区別します。これにより、画像全体を包括的に理解することが可能となりました。

出典: Kirillov, A., He, K., Girshick, R., Rother, C., & Dollár, P. (2018). Panoptic Segmentation.
arXiv preprint arXiv:1801.00868.
https://arxiv.org/abs/1801.00868 本図は教育目的で引用しています。
キーワードまとめ
スキップコネクション、アップサンプリング、インスタンスセグメンテーション、パノプティックセグメンテーション(Panoptic Segmentation)
この分野の理解度をチェック!
最新シラバス対応のオリジナル模試で、本番レベルの問題に挑戦しませんか?
E資格オリジナル模試を見る →