物体検出
0.章の概要
この章では、物体検出に関連する代表的な手法について解説します。まず、R-CNNファミリーとMask R-CNNといった精度重視の2ステージ検出モデルについて学びます。次に、YOLOやSSDのような高速性を追求した1ステージ検出モデルを紹介します。最後に、アンカーを不要にした新しい設計思想を持つFCOSについて解説し、これらの手法の違いや進化の背景を説明していきます。
物体検出の進化をたどり、どのようにしてAIが「目」を手に入れたのか、その秘密を紐解いていきましょう。
1. Faster R-CNN, Mask R-CNN
学習キーワード: Bounding Box、mAP、ROI、end-to-end、2ステージ検出、Selective Search、Fast R-CNN、Region Proposal Network (RPN)、Anchor Box、アンカー、ROI Pooling、ROI Align、インスタンスセグメンテーション
概要
物体検出の進化は、R-CNNから始まり、Fast R-CNN、そしてFaster R-CNNへと大きく進化してきました。これらの手法は、いずれも2段階の「候補領域の生成」と「物体の分類・精査」を行う2ステージ検出に基づいていますが、それぞれ独自の改良点が計算効率や精度の向上をもたらしました。ここでは、進化の順序にしがって解説を進めていきます。
R-CNN
R-CNNは、物体検出の基本形として登場しました。
以下に全体の流れを示します。
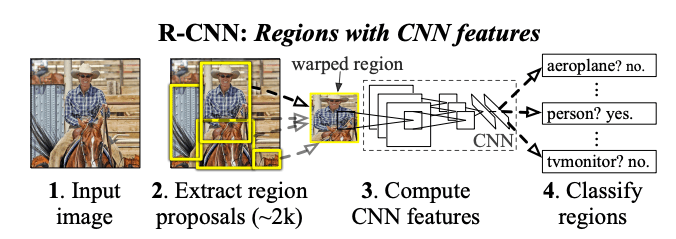
出典: Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2014). Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation.
arXiv preprint arXiv:1311.2524.
https://arxiv.org/abs/1311.2524 本図は教育目的で引用しています。
-
Selective Searchを用いて、画像中から数千個の候補領域(ROI)を抽出(この処理は領域提案(Region Proposal)といわれます)。
Selective Searchでは、以下の手順で候補領域を生成します:- 入力画像を小さなセグメントに分割(色合いや濃淡勾配などを元に分割)。
- 隣接するセグメントを類似度に基づいて統合しながら、階層的に領域を形成。
- この過程で様々なサイズと形状の候補領域を生成。
- 各候補領域をCNNに通して固定長の特徴ベクトルへ変換(論文ではAlexNetを使用)。
- 各候補領域について、SVMを用いて物体のクラス分類を実施。さらに、バウンディングボックスの正確な位置の数値を回帰モデルで推定。
評価指標1: 候補領域の精度は、IoU (Intersection over Union)を用いて評価されます。IoUは、推定されたBounding Boxと正解のBounding Boxの重なり具合を計算する指標で、次の式で定義されます:

例えば、IoUが一定の閾値(例: 0.5)以上であれば、検出が正確とみなされます。
評価指標2:物体検出モデルの性能を評価するための指標の一つにmAP(mean Average Precision)があります。mAPは、モデルが検出したBounding Box(物体領域)が正解(Ground Truth)にどれだけ正確に一致しているかを示します。具体的には、以下の手順で計算されます。
- 検出されたオブジェクトの位置が正解の位置と一定の閾値(IoU)以上の重なり具合を満たす場合に、検出を正解としてカウントします。
- 検出されたオブジェクトのクラスが正解のクラスと一致する場合に、検出を正解としてカウントします。
- 検出結果を Precision-Recall (PR) 曲線にプロットし、曲線下の面積 (AP: Average Precision) を計算します。
- APをクラスごとに計算し、クラスごとのAPを平均してmAPを算出します。
mAPは、物体検出モデルの位置とクラスの精度を総合的に評価する指標として広く使用されています。
R-CNNの課題:
- 候補領域ごとに個別にCNNを適用するため、計算コストが非常に高く、処理速度が遅い。
- Selective Search自体も計算負荷が高い。
- CNNに渡される前に画像が固定サイズにリサイズされてしまうため、不自然な入力画像となる。(AlexNetは227x227のサイズしか受けとれない)
Fast R-CNN
Fast R-CNNは、画像全体を1回CNNに通し、共有された特徴マップを生成することで、R-CNNの問題点であった計算効率を大幅に改善しました。
以下に全体の流れを示します。
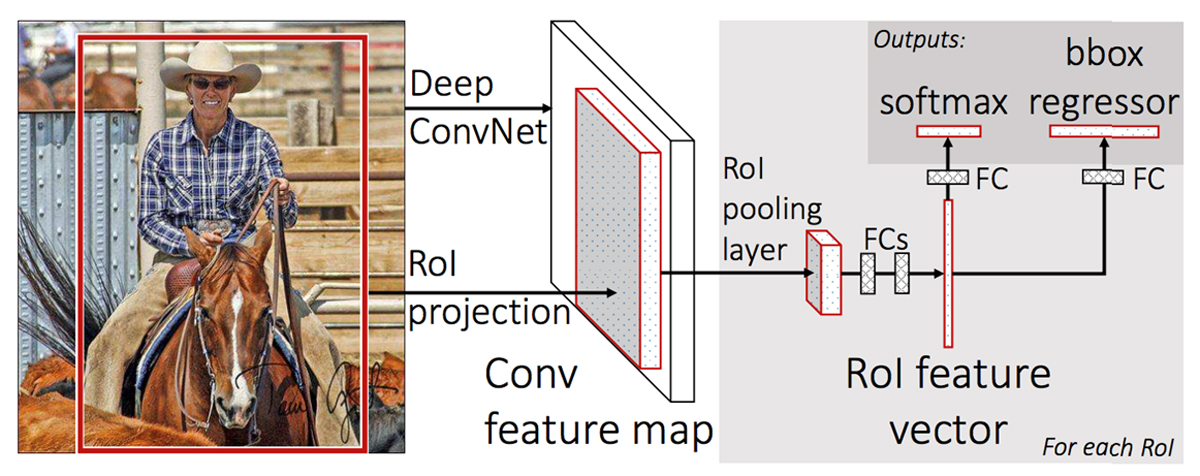
出典: Girshick, R. (2015). Fast R-CNN.
arXiv preprint arXiv:1504.08083.
https://arxiv.org/abs/1504.08083 本図は教育目的で引用しています。
- 画像全体を1回CNNに通して共有された特徴マップを生成。
- 出力された特徴マップに対し、Selective Searchで抽出した候補領域をROI Poolingで固定サイズの特徴ベクトルに変換。
- 1つのネットワークで、クラス分類とBounding Box回帰を同時に実施。(Multi-task Lossを使用)
ROI Pooling
ROI Poolingは、Fast R-CNNで導入された処理で、候補領域を固定サイズの特徴ベクトルに変換するための手法です。この手法により、候補領域ごとにCNNを適用する必要がなくなり、計算速度が向上しました。
具体的には、候補領域内の特徴マップを一定のサイズに分割し、それぞれの領域の最大値を取り出すことで固定サイズの特徴ベクトルを生成します。
以下に出力サイズを2×2とした際のROI Poolingの流れを図で示します。

※ROI Poolingの問題点として、ROIを固定サイズのグリッドに分割する際、元のピクセル座標を最近傍または四捨五入で量子化するため、ピクセル情報が失われ、位置精度が低下し、小さな物体検出精度が低いことが挙げられます。(これらの問題を解決するために登場したのが後述するROI Alignです。)
Multi-task Loss
Fast R-CNNでは、クラス分類とBounding Box回帰の2つのタスクを同時に学習するために、Multi-task Lossを使用します。
ここで、\( L_{cls} \)はクラス分類の損失、\( L_{loc} \)は位置の損失です。また、\( \lambda \)は損失の重みです。
このように、Fast R-CNNは、クラス分類と位置の回帰を同時に学習することで、物体検出の性能を向上させます。
課題:計算速度は向上したが、候補領域の生成には依然としてSelective Searchが必要で、これがボトルネックであることには変わりありませんでした。
Faster R-CNN
Faster R-CNNは、候補領域生成を高速化するためにRegion Proposal Network (RPN)を導入し、Selective Searchを完全に置き換え、end-to-endで学習できるようにしたアーキテクチャです。
以下に全体の流れを示します。
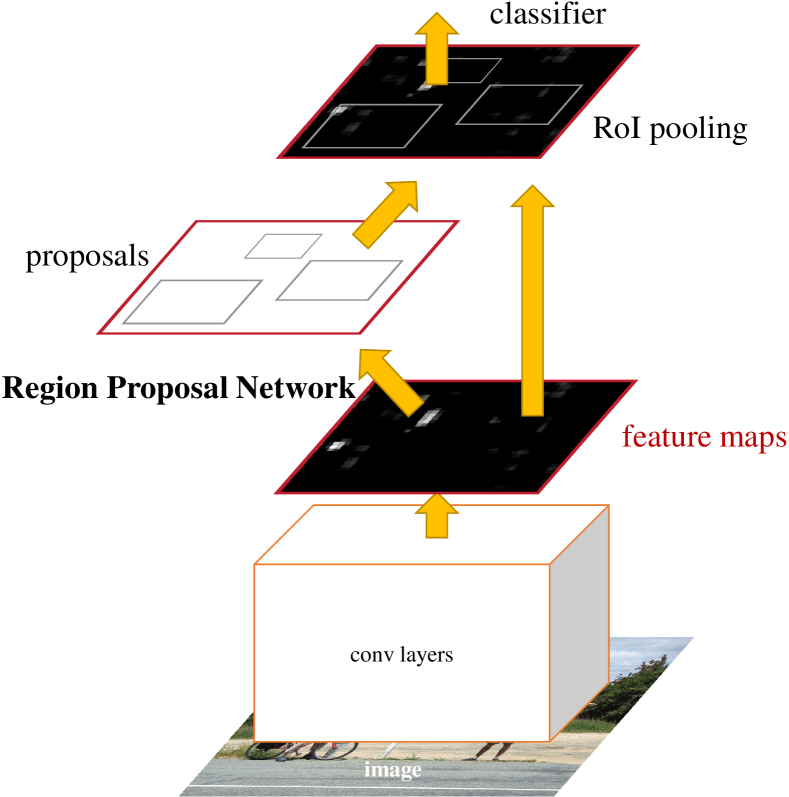
出典: Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks.
arXiv preprint arXiv:1506.01497.
https://arxiv.org/abs/1506.01497 本図は教育目的で引用しています。
- 画像をCNNに通し、特徴マップを生成(論文ではVGG、ResNetを使用)。
- 物体候補領域の生成 (RPN:Region Proposal Network):
- 画像の特徴マップを基に、物体が存在しそうな領域(Region Proposals)を生成。
- 異なるサイズやアスペクト比をカバーするため、中央をアンカーとして、事前定義されたk個のAnchor Boxを作成。
- 物体の精査と分類:
- RPNで生成された提案領域にROI Poolingを適用し、固定サイズに変換。
- 最終的に分類とBounding Box回帰を行う。
アンカー
異なるサイズやアスペクト比を持つ複数の矩形を事前に定義しておくことで、さまざまな形状の物体を検出する能力を向上させます。
出典: Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks.
arXiv preprint arXiv:1506.01497.
https://arxiv.org/abs/1506.01497 本図は教育目的で引用しています。
上図で示すように、
- アンカーボックス一つにつき、k個のアスペクト比を適応する。
- それぞれに対して、物体か背景か2値分類を行う(2k個のスコアを算出)。
- アンカーボックスの座標(x,y)とサイズ(H,W)の4つの情報を、回帰予測する(4k個の値を算出)。
Faster R-CNNは、RPNを導入したことでend-to-endで学習可能な2ステージ検出モデルとなり、計算効率と精度が大幅に向上しました。
RNNファミリーのまとめ(重要ポイント!!)
| 手法 | 候補領域抽出 | 特徴抽出 | 推論の速度 | 主な改善点 |
|---|---|---|---|---|
| R-CNN | Selective Search | 個別にCNN適用 | 遅い | 特徴抽出のCNNの適用を初めて導入 |
| Fast R-CNN | Selective Search | 共有されたCNN | 速い | CNN計算の共有化、ROIプーリング |
| Faster R-CNN | RPN | 共有されたCNN | さらに速い | Selective SearchをRPNに置換 |
Mask R-CNN
Mask R-CNNは、Faster R-CNNを拡張し、物体検出と同時にインスタンスセグメンテーション(各物体の領域をピクセル単位で識別)を可能にしたアルゴリズムです。物体の「どこにあるか」だけでなく、「その形状は何か」をも出力します。
出典: He, K., Gkioxari, G., Dollár, P., & Girshick, R. (2017). Mask R-CNN.
arXiv preprint arXiv:1703.06870.
https://arxiv.org/abs/1703.06870 本図は教育目的で引用しています。
Mask R-CNNは、Faster R-CNNに以下の機能を追加しています:
- セグメンテーションの出力:Faster R-CNNではBounding Box(矩形領域)の検出がゴールでしたが、Mask R-CNNはBounding Boxに加えて、物体ごとのピクセル単位のマスクを生成します。
- ROI Alignの導入:Faster R-CNNで用いられていたROI Poolingは、量子化による情報損失が問題でした。Mask R-CNNでは、ROI Alignを採用することで、座標を正確に処理し、セグメンテーション精度を向上させています。
- マスクブランチ:物体のマスク(形状)を生成するための追加のサブネットワークです。このブランチは、各ROIから対応するピクセル単位の二値マスク(物体か背景か)を予測します。
ROI Align
ROI AlignはROI Poolingの改良版であり、特にセグメンテーションや小さな物体の検出で有効です。処理は以下の手順で行われます。
-
固定サイズグリッドの定義
ROI領域を指定された出力サイズ(例えば7×7)の固定サイズグリッドに等間隔で分割します。このグリッドの各セルは、ROI領域内の特定のサブ領域に対応します。 -
ピクセル座標を小数点まで保持
従来のROI Poolingのように座標を整数値に丸める(量子化する)のではなく、小数点以下の精度を保ったままROI領域を特徴マップ上にマッピングします。これにより、座標変換時の情報損失を防ぎます。 -
バイリニア補間
各グリッドセル内で必要な特徴量を取得する際、サンプリングポイントが小数点座標になる場合があります。この座標に対応する特徴量は、周囲4つのピクセル値を距離に応じて重み付けして計算するバイリニア補間を用いて求めます。これにより、グリッドの各点で高精度な特徴量を取得できます。
損失関数
Mask R-CNNの損失関数は、以下の3つの損失の合計として定義されます:
\( \mathcal{L}_{cls} \) : クラス分類の損失(クロスエントロピー損失)
\( \mathcal{L}_{box} \) : Bounding Box回帰の損失(スムーズL1損失)
\( \mathcal{L}_{mask} \) : セグメンテーションマスク生成の損失(二値クロスエントロピー損失)
マスク損失 \( \mathcal{L}_{mask} \) は、各ROIごとにクラス特化型のマスクを生成する際に計算されます。
関連用語の補足
- Non-Maximum Suppression (NMS):候補領域が多く重複する場合、最もスコアの高い領域を選び、他の重複領域を抑制する手法です。これにより、冗長な検出を防ぎます。(詳細は後述)
- Bounding Box:物体検出モデルが検出した物体を囲む矩形領域。
- マルチタスク学習:複数のタスクを同時に学習する手法。例えば、物体検出モデルでは、クラス分類と位置の回帰を同時に学習することによって、共通の特徴量を発見でき、精度向上に繋がることがあります。
- end to end:データの入力から出力までの全ての処理を一つのモデルで行うアプローチを指します。
2. YOLO, SSD
学習キーワード: 1ステージ検出、デフォルトボックス、Non-Maximum Suppression (NMS)、ハードネガティブマイニング
概要
YOLO(You Only Look Once)とSSD(Single Shot MultiBox Detector)は、高速性を重視した1ステージ検出モデルです。
YOLO
YOLO(You Only Look Once)は、画像を固定サイズのグリッドに分割し、各グリッドで物体を検出します。他の物体検出モデルと異なり、画像全体を一回の予測で処理することが可能となりました。初登場時のモデルは、Faster R-CNNに識別精度は少し劣りますが高速な検出速度を実現しました。
YOLOの処理手順は、以下の通りです。
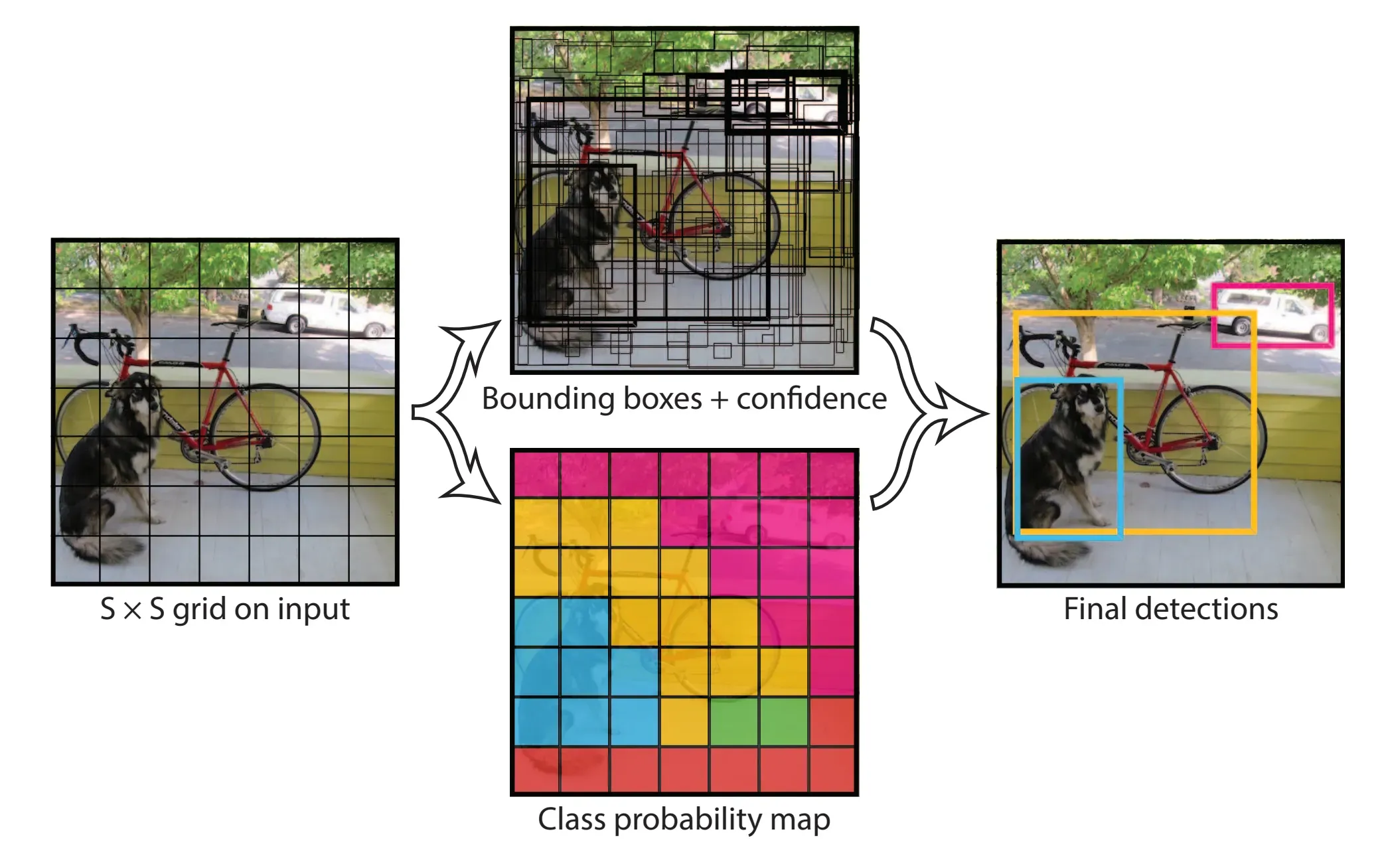
出典: Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You Only Look Once: Unified, Real-Time Object Detection.
In *Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)* (pp. 779-788).
https://arxiv.org/abs/1506.02640本図は教育目的で引用しています。
- grid cell:画像を固定サイズのグリッドに分割します。
- class probability map:各グリッド内の物体の種類(クラス)の推定します。
- Bounding Box:各グリッドに対して、n個のバウンディングボックスを推定し、それぞれで中心座標値、幅、高さ、物体である信頼度、計5つの値を出力します。
- NMS(Non-Maximum Suppression):全てのグリッドで予測されたBounding Boxの重複を削減します。
- :最後に、Bounding BoxとClass probability mapを結合し、残ったBounding Boxとそのクラススコアを出力します。
NMS(Non-Maximum Suppression)
NMS (Non-Maximum Suppression) は、物体検出アルゴリズムで使用される後処理ステップであり、特に重複して検出されたバウンディングボックスを整理するために用いられます。この手法により、同じ物体に対応する複数の予測が一つに統合され、結果がシンプルにすることができます。
処理の流れは以下のようにシンプルです。
-
予測結果の取得
モデルから出力されるバウンディングボックスの情報を取得します。- 各ボックスの座標、高さ、幅
- 各ボックスのクラス(何の物体か)
- スコア(信頼度)
-
スコアによるソート
予測されたスコアが高い順にバウンディングボックスを並べ替えます。 -
重複の処理(抑制)
以下の手順を実行します:- スコアが最も高いボックスを選び、基準として残します。
- 他のすべてのボックスについて、基準ボックスとの IoU (Intersection over Union) を計算します。
- IoUが設定した閾値(一般的な設定としては 0.5)を超えるボックスを削除します。
-
繰り返し
残ったボックスに対して同じ処理を繰り返します。
損失関数
YOLOの損失関数は、以下の5つの要素から構成されます:
\( + \lambda_{\text{coord}} \sum_{i=0}^{S^2} \sum_{j=0}^B \mathbb{1}_{ij}^{obj} [(w_i - \hat{w}_i)^2 + (h_i - \hat{h}_i)^2] \)
\( + \sum_{i=0}^{S^2} \sum_{j=0}^B \mathbb{1}_{ij}^{obj} (C_i - \hat{C}_i)^2\)
\( + \lambda_{\text{noobj}} \sum_{i=0}^{S^2} \sum_{j=0}^B \mathbb{1}_{ij}^{noobj} (C_i - \hat{C}_i)^2 \)
\( + \sum_{i=0}^{S^2} \mathbb{1}_{i}^{obj} \sum_{c \in classes} (p_i(c) - \hat{p}_i(c))^2 \)
変数の説明:
- \(\lambda_{\text{coord}}\): 座標の損失に対する重み
- \(\lambda_{\text{noobj}}\): 非物体(背景)に対する重み
- \(S\): グリッドのサイズ
- \(B\): バウンディングボックスの数
- \(\mathbb{1}_{ij}^{obj}\): オブジェクトが存在するかどうかを示すインジケータ関数
- \(\mathbb{1}_{ij}^{noobj}\): オブジェクトが存在しない(背景)かどうかを示すインジケータ関数
- \(x_i, y_i, w_i, h_i\): 予測されたバウンディングボックスの座標とサイズ
- \(\hat{x}_i, \hat{y}_i, \hat{w}_i, \hat{h}_i\): 実際のバウンディングボックスの座標とサイズ
- \(C_i, \hat{C}_i\): 予測されたオブジェクトの信頼度と実際の信頼度
- \(p_i(c), \hat{p}_i(c)\): 予測されたクラススコアと実際のクラススコア
- \(classes\): 予測可能なクラスの集合
1行目はバウンディングボックスの座標の損失を表し、2行目はバウンディングボックスの幅と高さの損失を表します。3行目は物体である信頼度の損失を表し、4行目は非物体(背景)である信頼度の損失を表します。5行目はクラス予測の損失を表します。
まとめ
特徴をまとめると以下の通りです。
- 他の物体検出モデルと異なり、画像全体を一回の予測で処理するため、高速に物体検出を可能。
- 処理が一つのネットワークで完結するため、計算コストが低く、リアルタイムでの物体検出が可能。
- 物体検出を分類問題ではなく、回帰問題としてモデル化しているため、物体の位置やサイズを直接予測することが可能。
課題:グリッド内で識別できるクラスは1つのため、他の物体検出モデルと同じく、小さい物体や複雑な背景での検出性能が低いという問題があります。これらの問題を解決するために、YOLOの改良版であるYOLOv2、YOLOv3、YOLOv4などが提案されています。
SSD
SSD(Single Shot MultiBox Detector)は、YOLOとは異なり、複数の特徴マップを使用して物体のスケールに応じた高精度な検出を行います。YOLOがリアルタイム性を重視するのに対し、SSDは小さな物体も得意とし、特に多様なサイズの物体が含まれるシーンで優れた性能を発揮します。しかし、計算コストはやや高く、リアルタイム性ではYOLOに劣ります。
SSDの処理手順は以下の通りです。
- 入力画像を指定されたサイズ(例: 300x300)にリサイズし、バックボーン(例: VGG-16)を使用して特徴マップを生成します。
- 各特徴マップに対して、異なるサイズとアスペクト比のデフォルトボックスを適用します。
- デフォルトボックスに対して、Bounding Boxの位置(中心座標、幅、高さ)とクラス(物体カテゴリや背景)のスコアを予測します。
- すべての予測結果に対して、Non-Maximum Suppression (NMS)を使用して重複するボックスを削除し、最適な結果を選択します。
デフォルトボックス
SSDは、各特徴マップ上の各グリッドセルに対して、事前定義された異なるサイズとアスペクト比のデフォルトボックスを割り当てます。これにより、物体のスケールやアスペクト比に柔軟に対応し、様々なサイズの物体検出が可能になります。
デフォルトボックスはなかなかイメージが湧きづらい内容です。ここでは簡単に説明しましたが、以下サイトではデフォルトボックス含めSSDのアルゴリズムがわかりやすく解説されているので、興味のある方はご参考下さい
ハードネガティブマイニング
ハードネガティブマイニングは、物体検出の訓練における負例(ネガティブサンプル)の不均衡を解消し、効率的な最適化と安定した訓練を実現するための手法です。以下にその手順を示します。
- 初期ボックスの生成
物体検出モデルはまず、画像に対して予測を行い、初期のバウンディングボックス(候補領域)を生成します。この段階で、多くの初期ボックスは負例(物体が存在しない場所)となります。 - 負例と正例の不均衡
初期ボックスの多くは負例となるため、負例と正例の間に大きな不均衡が生じます。通常、負例の方が圧倒的に多くなるため、すべての負例を使うと学習が効率的に進まなくなります。 - Confidence loss でのソート
モデルが予測した各バウンディングボックスに対して、その予測信頼度(confidence score)を計算します。このスコアを基に、負例の中で誤分類されている負例(難しい負例)を特定します。
この段階では、負例が信頼度の高い順にソートされ、難しい負例に重点を置いて選びます。 - 負と正の比率の制限
学習に使用する正例と負例の比率を最大でも3:1に制限します。これにより、負例が多すぎて学習が偏ることを防ぎ、訓練データのバランスを保ちます。 - 選択した負例の学習への使用
ソートされた負例の中で、最も重要とされる(難しい)負例だけを学習に使用します。これにより、モデルは誤分類されやすい領域を特に学習し、より高精度な識別能力を身に付けます。 - 訓練の繰り返し
このプロセスを繰り返し行うことで、モデルは負例に対する識別能力を高め、特に難しい負例に対する性能を向上させます。最終的に、学習の収束が速く、訓練が安定したものになります。
この手法は、モデルが多くの負例に対して適切に学習し、特に誤分類を減らすことができるため、効率的かつ安定した学習を実現します。
関連用語の補足
- YOLOv2(YOLO9000):YOLOの改良版で、精度、速度、分類クラス数を向上させた19層のアーキテクチャです。バッチ正規化、K-means、DarkNet-19、ImageNet+COCOの学習を組み合わせて9000クラスの物体検出を実現しました。
- YOLO v3:YOLOv2の更なる改良版で、特に小さい物体の検出性能が向上しました。さらに、ダークネット53という新しいバックボーンネットワークを導入し、計算コストを削減しながら精度を維持しました。
3. FCOS
学習キーワード: アンカーフリー(Anchor-Free)、Feature Pyramid Network(FPN)、センターネス(Center-ness)、アンビギュアスサンプル
概要
FCOS(Fully Convolutional One-Stage Object Detection)は、アンカーボックスを用いずに、画像中の各ピクセルに直接物体の存在確率とBounding Boxの位置を予測させる手法です。従来のYOLOやSSDでは、物体検出手法ではアンカーの設計や複雑な計算処理が必要でしたが、FCOSはアンカーを必要とせずに高精度の物体検出に成功しています。
FCOSを理解するには以下の3点が重要になります。
- アンカーフリー:提案領域生成のためのアンカーを使わず、シンプルで効率的。
- Feature Pyramid Network (FPN):異なるスケールの物体を効果的に検出。
- センターネス(Center-ness):バウンディングボックスの中心に近い予測を優先。
FCOSの構造を以下に示します。
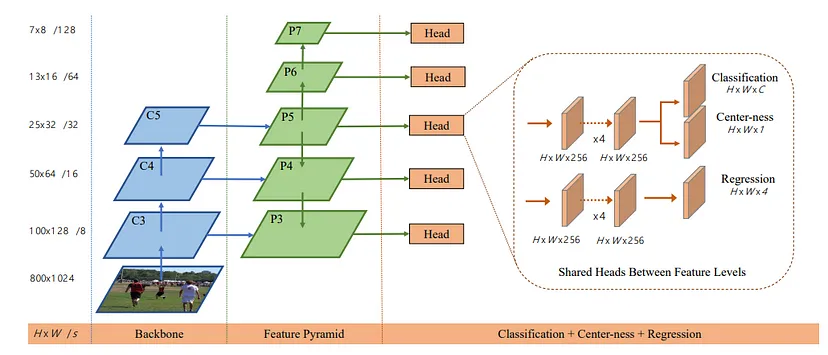
出典: Tian, Z., Shen, C., Chen, H., & He, T. (2019). FCOS: Fully Convolutional One-Stage Object Detection.
arXiv preprint arXiv:1904.01355.
https://arxiv.org/abs/1904.01355 本図は教育目的で引用しています。
FCOSの処理の概要
- Feature Pyramid Network (FPN):異なるスケールの物体を効果的に検出するためのFPNを適用し、特徴マップを生成。
- Head:FPNの出力をHeadに渡し、物体の存在確率とバウンディングボックスの位置を予測。Headには、Classification、Regression、Center-nessの3つのタスクがあります。
- Classification:物体のクラスを予測し、物体の種類を決定します。
- Regression:バウンディングボックスの位置とサイズを予測し、物体の位置を決定します。
- Center-ness:バウンディングボックスの中心に近い予測を優先するためのセンターネスを計算。
アンカーフリーモデル
FCOSは、従来の物体検出手法(Faster R-CNNやSSDなど)が使用するAnchor Boxを必要としないため、アンカーフリーモデルとして知られています。
アンカーボックスモデルの課題
- ネガティブサンプルとポジティブサンプルはIOUにて区別するため、ほとんどのAnchor Boxがネガティブサンプルになってしまう。
- Anchor Boxのサイズやアスペクト比を事前に設計する必要があり、それにより精度が上下してしまう。(←これが結構手間)
FCOSによる改善
- 特徴マップ内のある点と正解ラベル(物体が位置する範囲)の上下左右距離を使用するため、複数のAnchor Boxが不要。
- 特徴マップ上のある点が、物体のground truthのバウンディングボックス内にあれば、ポジティブサンプル判定のため、ネガティブサンプルとポジティブサンプルの不均衡を改善。
- Anchor Boxのアスペクト比の調整も不要。
FOCSではアンカーのチューニングが不要となり、モデルがシンプルかつ効率的になりました。
ポジティブサンプル、ネガティブサンプル、アンビギュアスサンプル

出典: Tian, Z., Shen, C., Chen, H., & He, T. (2019). FCOS: Fully Convolutional One-Stage Object Detection.
arXiv preprint arXiv:1904.01355.
https://arxiv.org/abs/1904.01355 本図は教育目的で引用しています。
- ポジティブサンプル:物体のバウンディングボックスの内部に位置し、その物体の中心点または周辺に属するピクセルのことを指します。
- アンビギュアスサンプル:Ambiguous Sampleとは、複数の物体のBounding Boxに重なり、それがどの物体に属するか明確でないピクセルのことを指します。
- ネガティブサンプル:背景
アンカーボックスモデルは、特徴マップ内の各点に対してn個のアンカーボックスを計算していたが、FCOSは特徴マップ上の各点と正解ラベルの上下左右4点の位置関係のみ計算すれば良いので、サンプル数を大幅に減らし、学習速度を向上できました。
Feature Pyramid Network (FPN)
Feature Pyramid Network (FPN)は、異なるスケール(小さな物体)の物体を検出するための手法です。画像には、小さな物体(例:小鳥、スマートフォン)と大きな物体(例:車、建物)が同時に存在します。小型物体の検出には、高解像度の詳細な情報が必要であり、大型物体の検出には、低解像度での広い範囲の情報が重要になります。
一般的なCNN(例:ResNet)は、畳み込み処理を進めるにつれて解像度が低くなり、高次元の抽象的な特徴を抽出するため、高次元の抽象的な特徴をそのまま物体検出に使うと、小型物体を見逃す原因になります。
FPNの仕組み
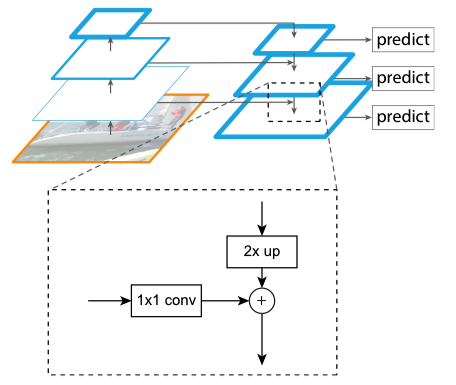
出典: Lin, T.-Y., Dollár, P., Girshick, R., He, K., Hariharan, B., & Belongie, S. (2017).
Feature Pyramid Networks for Object Detection.
arXiv preprint arXiv:1612.03144.
https://arxiv.org/abs/1612.03144 本図は教育目的で引用しています。
- 特徴マップの抽出:画像をCNN(例:ResNet)に入力し、各段階で特徴マップを生成。
- アップサンプリング:高レベル(低解像度)の特徴マップを低レベル(高解像度)にアップサンプリング。
- 特徴統合:低レベルの特徴マップに、アップサンプリングしたものを加えていき、低レベル(高解像度)の精度を上げ、小さい物体の識別能を強化。
センターネス(Center-ness)
センターネスは、物体の中心に近いピクセルを優先するためのスコアです。
アンカーフリーモデルでは、正解ラベル内の全ての点をポジティブサンプル(またはアンビギュアスサンプル)としますが、物体の境界近くにあるピクセルも中心点と誤認される可能性があり、物体の中心から離れた点からバウンディングボックスを予想した時に予測精度が悪くなる事がありました。センターネスではその問題点を解決しています。
センターネスの計算式

出典: Lin, T.-Y., Dollár, P., Girshick, R., He, K., Hariharan, B., & Belongie, S. (2017).
Feature Pyramid Networks for Object Detection.
arXiv preprint arXiv:1612.03144.
https://arxiv.org/abs/1612.03144 本図は教育目的で引用しています。
\(l, r, t, b\):物体の中心からBounding Boxの左、右、上、下の距離。
センターネススコアは、物体の中心に近いほど1に近づき、境界に近いほど0に近づくように設計されており、バイナリークロスエントロピー誤差を用いて計算されます。
具体的には、テスト時のクラス分類スコアにセンターネスをかけることで、物体の中心から離れたバウンディングボックスのスコアを小さくしています。
損失関数
FCOSの損失関数は、以下の式で表されます:
ここで、以下の変数が使用されています。
- \(L_{cls}\): 焦点誤差(Focal Loss)
- \(L_{reg}\): IoU誤差
- \(N_{pos}\): ポジティブサンプルの数
- \(p_{x,y}\): 正解クラスのスコア
- \(\lambda\): ハイパーパラメータ。\(L_{reg}\)のバランスウェイト
- \(c_{x,y}^*\): センターネス
- \(\mathbb{1}_{c_{x,y}^* > 0}\): 指示関数(条件を満たせば1、それ以外は0)
この式の第一項はクラス分類の損失を表し、第二項は位置の回帰の損失を表しています。
関連用語の補足
- Focal Loss:クラス不均衡問題に対処するために設計されており、少数クラスのサンプルに対する損失を増加させることで、モデルが少数クラスに対しても適切に学習することを促します。
キーワードまとめ
Bounding Box、mAP、ROI、end-to-end、2ステージ検出、Selective Search、Fast R-CNN、Region Proposal Network (RPN)、Anchor box、アンカー、ROI Pooling、ROI Align、インスタンスセグメンテーション、1ステージ検出、デフォルトボックス、Non-Maximum Suppression (NMS)、ハードネガティブマイニング、アンカーフリー(Anchor-Free)、Feature Pyramid Network(FPN)、センターネス(Center-ness)、アンビギュアスサンプル
この分野の理解度をチェック!
最新シラバス対応のオリジナル模試で、本番レベルの問題に挑戦しませんか?
E資格オリジナル模試を見る →