自然言語処理
- 0.概要
- 1. WordEmbedding
- 2. BERT
- 3. GPT-n
- キーワードまとめ
Contents
0.章の概要
この章では、自然言語処理(NLP)の基本概念と主要技術について詳しく解説します。特に、WordEmbedding、BERT、GPT-nといった重要な手法に焦点を当て、各技術の概要や応用例を紹介します。
1. Word Embedding
学習キーワード: 潜在的意味インデキシング(LSI)、Word2vec、n-gram、skip gram、CBOW、ネガティブサンプリング
概要
Word Embeddingは、単語をベクトル表現に変換する手法であり、単語間の意味的な関係を数値ベクトルとしてモデル化する技術です。例えば、「王様」と「女王」が近い意味を持つ場合、Word Embeddingではこれらの単語が近い位置に配置されます。この章では、単語がどのようにベクトル化され、どのように単語間の関係性を取得するのかをみていきます。
Bag of words
Bag of wordsは、文書を単語の集合として表現する手法です。具体的には、文書内の単語を一意の識別子(インデックス)に変換し、各単語の出現回数をカウントします。
例えば、次の文書があるとします。
| 文書 | 単語 |
|---|---|
| 文書1 | 私は学生です。 |
| 文書2 | 彼は学生です。 |
この文書に対して形態素解析を行い、Bag of wordsで表現すると、次のようになります。
| 文書 | 私 | は | 学生 | です。 | 彼 |
|---|---|---|---|---|---|
| 文書1 | 1 | 1 | 1 | 1 | 0 |
| 文書2 | 0 | 1 | 1 | 1 | 1 |
Bag of wordsは、このような表を使用して文書をベクトルで表現し、様々な解析に適用しやすくします。また、想像つくかと思いますが、文書の長さに応じて、情報量(ベクトルの次元)が膨大になります。
潜在的意味インデキシング(LSI)
LSI(Latent Semantic Indexing)は、情報検索や自然言語処理において、文書の意味的な関係を捉えるための手法の一つであり、単語の意味的な類似性を低次元空間で表現する方法です。Bag of wordsは扱う情報量が膨大であるため、文書内の単語の意味的な関係を捉えることができない、という問題に対処するために開発されました。検索などに用いられる次元圧縮手法でもあり、教師なし学習に分類されます。
LSIの仕組み
-
単語と文書のBag of wordsで表現
例えば、次のような行列を考えます:
文書1 文書2 文書3 文書4 文書5 単語A 3 0 1 2 0 単語B 2 1 0 1 2 単語C 0 4 2 0 1 単語D 1 2 0 1 0 -
特異値分解(SVD)で次元削減
Bag of wordsでベクトル化したデータを以下のように特異値分解(Singular Value Decomposition, SVD)で次元削減します。
\( A = U \Sigma V^T \)- \( A \): 単語と文書の共起行列
- \( U \): 単語のベクトル空間(単語の意味的特徴)
- \( \Sigma \): 特異値(次元の重要性を示す)
- \( V \): 文書のベクトル空間(文書の意味的特徴)
-
低次元空間で単語と文書を表現
次元削減の結果、単語と文書が低次元の意味空間にマッピングされます。 この空間では、関連性の高い単語や文書が近い位置に配置されます。
例として、次元削減した結果以下に示します。(※実際に計算したわけではありませんのでご了承ください。)
あるテーマに基づく文書1 あるテーマに基づく文書2 単語A 1.2 0.5 単語B 0.9 1.1 単語C 0.5 1.4 単語D 0.8 1.0 上記の結果によると、「単語B」と「単語D」は、文書1、文書2両方で値が近く、似た意味を持つた単語である可能性があると考えられます。
Word2vec
Word2vec(Word to Vector)は、単語をベクトル空間にマッピングするための手法で、自然言語処理において非常に重要な技術です。
以下に、Word2vecの主な特徴を示します。
- 分散表現: Word2vecは、単語を高次元のベクトルとして表現します。このベクトルは、単語間の意味的な関係を反映しており、意味が近い単語はベクトル空間でも近くに配置されます。これにより、単語の足し引きが可能になり、例えば「王様 - 男 + 女 = 女王様」という計算が行えるようになります。
- ニューラルネットワークの活用: Word2vecは、2層のニューラルネットワーク(またはロジスティック回帰)を使用して単語の分散表現を学習します。
- 代表的なモデル: Word2vecは、CBOW(Continuous Bag of Words)とSkip-gramという2つのモデルを使用して単語の学習を行います。CBOWは周辺単語から中心単語を予測し、Skip-gramは中心単語から周辺単語を予測します。
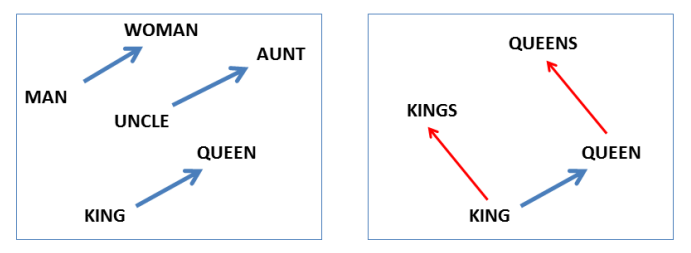
出典: Mikolov, T., Yih, W. T., & Zweig, G. (2013). Linguistic Regularities in Continuous Space Word Representations.
In *Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2013)* (pp. 746-751).
https://scottyih.org/publication/2013-05-27-0043 本図は教育目的で引用しています。
CBOW(Continuous Bag of Words)
CBOWは、周辺単語(指定のn個)から中心の単語を予測する手法です。
- 入力:周辺の単語
- 出力:中心の単語(単語ベクトルを求めたい単語)

モデルのどの部分が単語の意味ベクトルになるのか?
出力層側の隠れ層の重みが単語の意味ベクトルとなります。要は「単語ベクトルを求めるために、仮の予測モデルを作っている」ということです。実際に欲しいのは、出力層側の重みになります。
Skip-gram
Skip-gramは、中心の単語から周辺単語(指定のn個)を予測する手法です。
- 入力:中心の単語(単語ベクトルを求めたい単語)
- 出力:周辺の単語

モデルのどの部分が単語の意味ベクトルになるのか?
入力層側の隠れ層の重みが単語の意味ベクトルとなります。要は「単語ベクトルを求めるために、仮の予測モデルを作っている」ということです。実際に欲しいのは、入力層側の重みになります。
ネガティブサンプリング
ネガティブサンプリング(Negative Sampling)は、Word2vecの学習を効率化するために導入された手法です。Word2vecの出力層のノード数が多い(辞書の単語数くらいまで膨らむこともある)ため、計算量が大きくなりますが、ネガティブサンプリングを用いることで計算量を減らすことができます。簡単にまとめると、出力層の教師ラベルに該当しないノードをランダムに除外することで、計算量を削減するようなイメージです。
仕組み
- 正例の選択:正解である中心単語、または周辺単語を正例として選びます。
-
ネガティブ例の選択:正解の単語を除いた全単語の中から、5~20個程度の単語をサンプリングし、ネガティブ例として使用します。サンプリング方法は、単語頻度によって重みをつけますが、単語の個数に3/4乗することで頻出しない単語も適切にサンプリングすることができます。具体的には、ネガティブ例の単語 \(w_i\) が選ばれる確率は次の式で計算されます。
\( P(w_i) = \frac{|w_i|^{3/4}}{\sum_{j} |w_j|^{3/4}} \)ここで、\(w_i\) はサンプリング対象の単語、\(|w_i|\) は単語 \(w_i\) の出現頻度を表します。
- 2値分類:正例の単語と、サンプリングした数個のネガティブ例それぞれを2値分類に近似して扱い、学習していきます。(それぞれにシグモイド関数をかけ、2値交差エントロピー誤差を適用するイメージ)
これにより、計算コストを大幅に抑えつつ、正例とネガティブ例両方の学習を行うことができます。
関連用語の補足
- 形態素分析:文書を形態素(最小の意味を持つ単位)に分割し、それぞれの形態素の意味を解析すること。例えば、「私はサッカーが好きです」という文を「私」、「は」、「サッカー」、「が」、「好き」、「です」という形態素に分割し、それぞれの意味を解析する。
2. BERT
学習キーワード: Masked Language Modeling(MLM)、Next Sentence Prediction(NSP)、事前学習、ファインチューニング、positional embeddings、segment embeddings
概要
BERT(Bidirectional Encoder Representations from Transformers)は、2018年10月にGoogleが開発した自然言語処理(NLP)のモデルで、双方向の文脈理解を可能にするTransformerに基づいた手法です。これにより、従来の言語モデルの限界を克服し、文脈に基づいた単語の意味を正確に把握することができました。
登場当時は、11個のタスクで圧倒的SoTAを叩き出し、非常に注目を浴びたモデルです。
BERTの特長は、事前学習とファインチューニングという2段階の学習アプローチにあります。まず、大量のテキストデータで一般的な知識を学び、その後、特定のタスクに合わせてモデルを微調整していきます。
出典: Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
arXiv preprint arXiv:1810.04805.
https://arxiv.org/abs/1810.04805 本図は教育目的で引用しています。
アーキテクチャ
BERTは、Transformerのエンコーダ部分のみを使用しています。前後の文脈を双方向性に学習することで、文脈依存性をより深く理解することができています。
以下に他モデルと比較したBERTの概要図を示します。
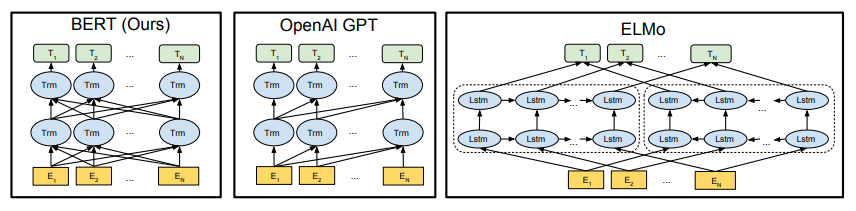
出典: Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
arXiv preprint arXiv:1810.04805.
https://arxiv.org/abs/1810.04805 本図は教育目的で引用しています。
BERTの論文では、以下の二つの大小モデルが作成されています。
- BERT-Base:12層のTransformerエンコーダを使用し、1.1億のパラメータを持つモデル。
- BERT-Large:24層のTransformerエンコーダを使用し、3.4億のパラメータを持つモデル。
事前学習
事前学習は、大規模なテキストデータを使って一般的な言語知識を学ばせるプロセスであり、以下の2つの重要なタスクを行います。
Masked Language Modeling(MLM)
MLMは、文の一部の単語を「マスク」して、その単語を予測するタスクです。これにより、BERTは文脈から単語を予測する能力を学習します。
例えば、「私は昨日___に行きました」という文が与えられた際、____部に入る単語を予測できるよう学習していきます(「公園」や「学校」など)。
MLMでは、入力文のランダムに選ばれた15%の単語をマスクし、その単語を予測します(実際には、マスクするトークンを常に[Mask]トークンに置き換えるのではなく、ランダムなトークンや、そのままにする、などの方法も取られています)。つまり、事前学習は教師ラベルの付いていない普通の文章を用いる「教師なし学習」になります。
Next Sentence Prediction(NSP)
NSPは、2つの文が続きとして正しいかどうかを予測するタスクです。これは、文と文の関係性を学ぶための手法です。
例えば、文1:「今日はいい天気です。」文2:「私は外に出かけました。」が入力データとして与えられた場合、文2が文1に続く可能性が高いかどうかを学習します。
NSPでは、学習サンプルの50%を文A、Bが連続したもの、50%を不連続なものに置き換えて学習しています。
ファインチューニング
事前学習で得られた一般的な言語知識を基に、ファインチューニングを行います。このプロセスでは、特定のタスクに合わせてモデルを微調整します。
センテンスペア分類タスク
- MNLI(Multi-Genre Natural Language Inference):文章の前提と結論の関係を推論するタスク
- QQP(Quora Question Pairs):質問のペアが似ているかどうかを判断するタスク
- QNLI(Question Natural Language Inference):質問と文章の関係を推論するタスク
- SWAG(Situations With Adversarial Generations):文章の続きを選択するタスク
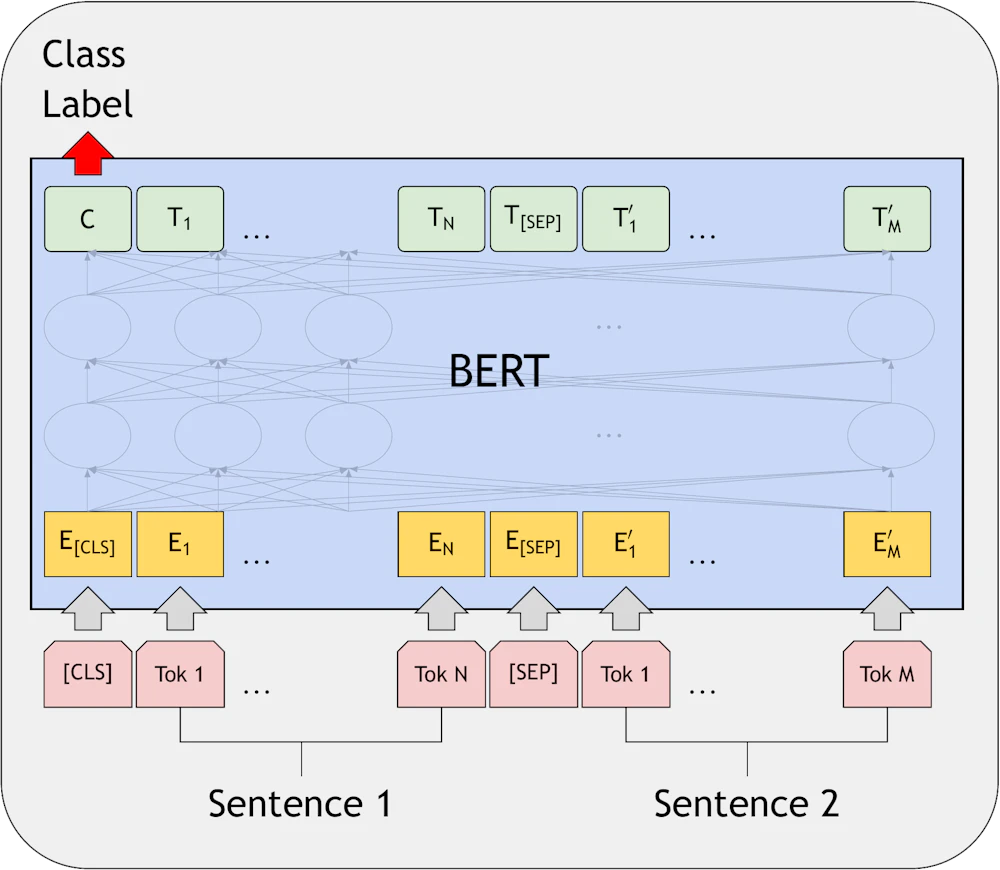
出典: Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
arXiv preprint arXiv:1810.04805.
https://arxiv.org/abs/1810.04805 本図は教育目的で引用しています。
1センテンス分類タスク
- SST-2(Stanford Sentiment Treebank): センテンスの感情を正の感情、負の感情に分類するタスク
- CoLA(Corpus of Linguistic Acceptability): センテンスの文法的正確さを評価するタスク

出典: Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
arXiv preprint arXiv:1810.04805.
https://arxiv.org/abs/1810.04805 本図は教育目的で引用しています。
質問回答タスク
- SQuADv1.1: Q&Aタスクで、質問文と答えを含む文章が渡され、答えがどこにあるかを予測するタスク
- SQuADv2.0: SQuAD v1.1に「答えが存在しない」という選択肢を加えたタスク
スタンフォード大学の質問応答データセット(SQuADv1.1およびSQuADv2.0)などの質問応答タスクにおいて、質問と回答のテキストスパンをマークします。
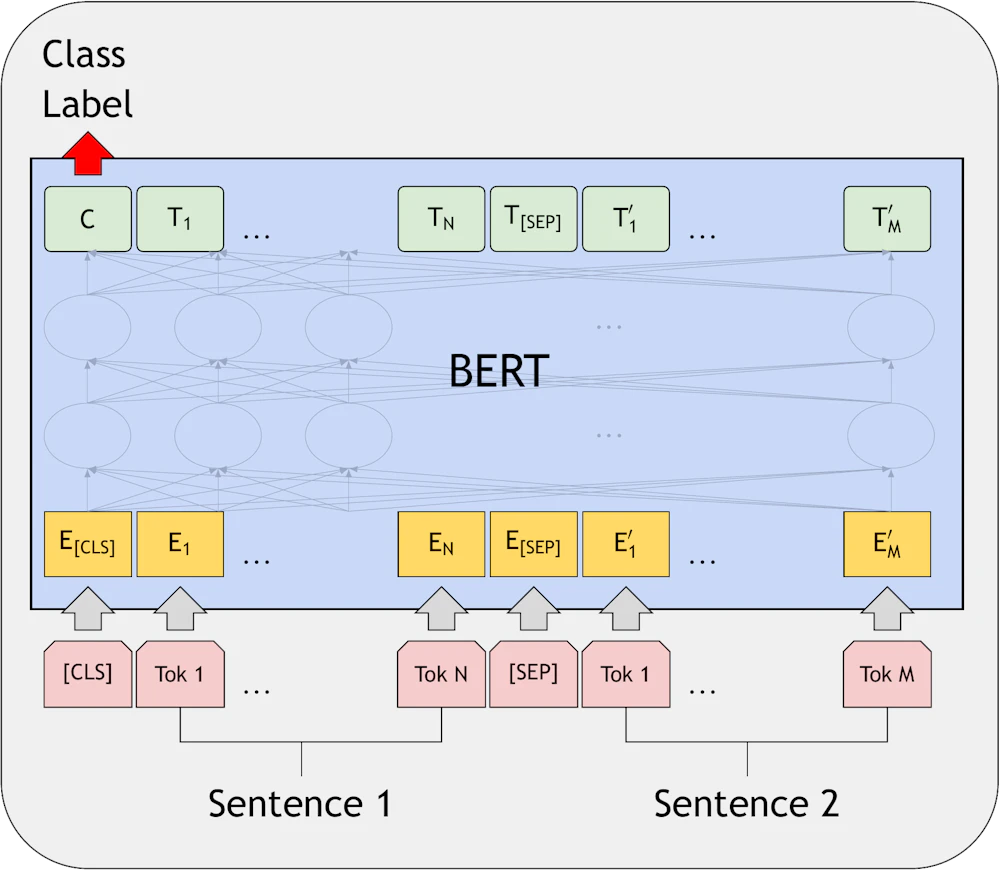
出典: Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
arXiv preprint arXiv:1810.04805.
https://arxiv.org/abs/1810.04805 本図は教育目的で引用しています。
BERTのエンコーダ入力の特徴
BERTでは、入力として、Word Embedding(単語の埋め込み)に加え、Positional Embeddings(位置埋め込み)とSegment Embeddings(セグメント埋め込み)を足したものが使用されます。
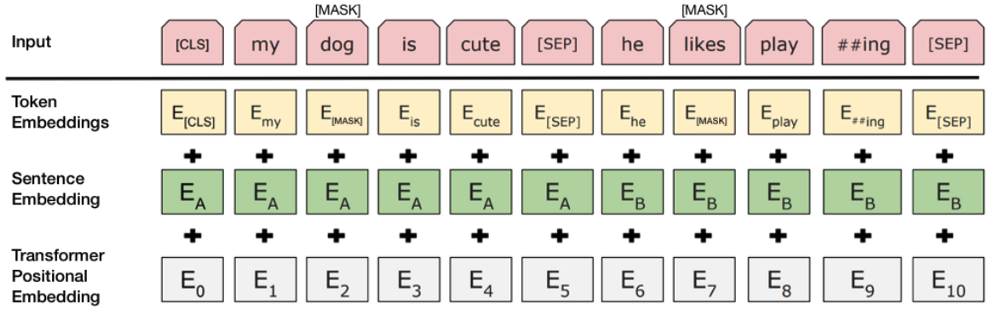
出典: Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
arXiv preprint arXiv:1810.04805.
https://arxiv.org/abs/1810.04805 本図は教育目的で引用しています。
Positional Embeddings(位置埋め込み)は、Transformer解説ページにて説明済みのため割愛します。
※transformerの解説はこちらから
Segment Embeddings(セグメント埋め込み)
BERTでは、2つの文(例えば、質問応答タスクでの質問と回答)を入力することがあります。これを区別するために、各単語にセグメント埋め込みを加えます。
関連用語の補足
- SoTA:State of the Artの略で、最先端の技術や研究を指します。具体的には、特定のタスクや分野における最高のスコアやパフォーマンスを達成したモデルや手法を指します。SoTAスコアは、研究者や開発者が自分のモデルや手法の性能を評価するための基準としてよく使用されます。
3. GPT-n
学習キーワード: 基盤モデル、Next token prediction、Few Shot learning、Zero Shot learning、Prompt Based Learning、RAG
概要
GPT-nは、OpenAIが開発した生成型言語モデル(Generative Pre-trained Transformer)の総称です。「n」はモデルのバージョンを表し、GPT-2、GPT-3、GPT-4と進化しています。GPT-nは、大規模なテキストデータを活用して事前学習され、ユーザーの入力(プロンプト)に応じて、人が書いたような自然なテキストを生成する能力を持ちます。
GPTの特徴は何といっても、自然言語処理における新しいパラダイムであるFew Shot LearningやZero Shot Learning(後述)を実現し、従来のタスク特化型モデルを超える精度を実現したことです。
GPT-nのアーキテクチャ
GPT-nは、トランスフォーマーのデコーダ部分に基づいて設計されており、GPTのEmbeddingは、Word Embedding(単語埋め込み)とPositional Embeddings(ポジション埋め込み)の和で行われています。学習は「ある単語の次に来る単語(トークン)」を予測するNext Token Prediction(自己回帰型の学習)を行い、自動的に文章を完成できるようになります。
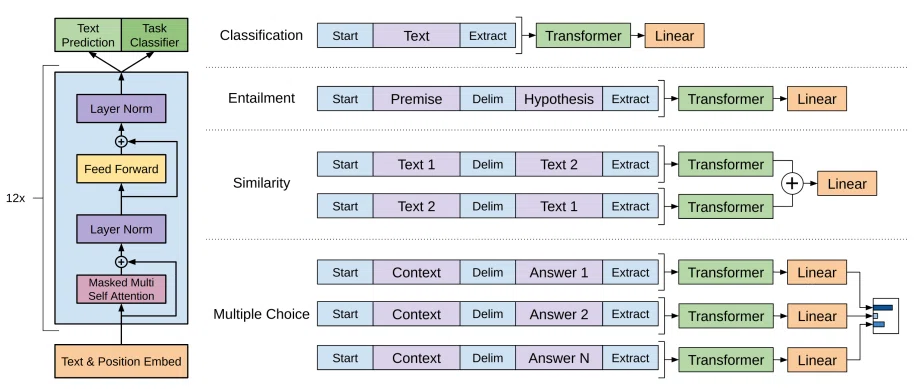
出典: Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving Language Understanding by Generative Pre-Training.
OpenAI, Research Paper.
https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
パラメータ数は以下の表に示す通り、バージョンが上がるごとに大幅に増加しています。
| モデル | パラメータ数 |
|---|---|
| GPT-1 | 1.2億 |
| GPT-2 | 15億 |
| GPT-3 | 1750億 |
| GPT-3.5 | 3550億 |
| GPT-4 | 1兆個以上 |
次に、各バージョンごとの特徴を解説します。
- GPT-1:最初のGPTモデル、単語埋め込みとポジション埋め込みを導入
- GPT-2:GPT-1の改良版、パラメータ数を増加させた、Layer NormalizationをTransformerブロックの最後に導入、Skip ConnectionをTransformerブロック内に導入
- GPT-3:GPT-2の改良版、パラメータ数をさらに増加させた、Sparse Transformer(Multi-head Attentionの軽量化)を導入
Few Shot Learning
Few Shot Learningは、モデルに数個(少数)の例を与えるだけで、新しいタスクを解決する能力を指します。従来はタスクごとに専用データセットで学習する必要がありましたが、GPT-nは少量の例を提示するだけで新しいタスクに適応することができます。
例として、プロンプトに「英語の文を日本語に翻訳する」というタスクの例を2〜3個提示するだけで、高精度な翻訳を行えます。
Zero Shot Learning
Zero Shot Learningは、モデルに例を一切与えずに、タスクの説明や指示(プロンプト)だけで新しいタスクを解く能力を指します。
例として、プロンプトに「この文をフランス語に翻訳してください。英語: I am happy.」と与えた場合でも、モデルはタスクの詳細な学習や例を必要とせず、「Je suis heureux.」と生成します。
Prompt-Based Learning
Prompt-Based Learningは、プロンプト(ユーザーがモデルに与える入力)を通じてモデルの挙動を調整し、特定のタスクを実行させる方法です。プロンプトの設計次第で、モデルの出力品質やタスク適応力をコントロールできます。
RAG(Retrieval-Augmented Generation)
RAG(検索拡張生成)は、LLMの回答精度を向上させるために、外部の知識ベースやドキュメントから関連情報を検索(Retrieval)し、その情報をプロンプトに付加してから生成(Generation)を行う手法です。
LLM単体では、事実と異なる内容をもっともらしく生成してしまう(ハルシネーション)ことがあり、また学習データに含まれない最新情報や専門的な知識について正確に回答することが難しい場合があります。RAGは、これらの課題を軽減するために以下のステップで動作します。
- 検索(Retrieval): ユーザーの質問に関連するドキュメントを、ベクトルデータベースなどから検索します。
- 拡張(Augmentation): 検索されたドキュメントの内容をプロンプトに追加し、コンテキストを補強します。
- 生成(Generation): 拡張されたプロンプトをLLMに入力し、より正確で根拠のある回答を生成します。
RAGは、ファインチューニングと比較してモデルの再学習が不要であり、知識ベースの更新によって比較的容易に最新情報へ対応できるという利点があります。ただし、検索精度やプロンプト設計に依存するため、常に正確な回答が得られるとは限りません。
GPT-3とBERTの主な違い
| モデル | 得意なタスク | 事前学習の手法 |
|---|---|---|
| GPTシリーズ | 要約、対話生成 | マスクされた単語より前のテキストを使用 |
| BERT | 質問応答、文の比較 | マスクされた単語の前後のテキストを使用 |
関連用語の補足
- 基盤モデル:基盤モデル(Foundation Model)とは、大量のテキストデータを使用して事前学習された汎用的なAIモデルを指します。
- Scaling Law:モデルがより大きなサイズになると、その性能が指数関数的に向上するという現象を指します。具体的には、Transformerの性能は、計算コスト(C)、データセットサイズ(D)、パラメータ数(M)の3つの変数のべき乗測に支配されていることが知られています。
キーワードまとめ
潜在的意味インデキシング(LSI)、Word2vec、n-gram、skip gram、CBOW、ネガティブサンプリング、Masked Language Modeling(MLM)、Next Sentence Prediction(NSP)、事前学習、ファインチューニング、positional embeddings、segment embeddings、基盤モデル、Next token prediction、Few Shot learning、Zero Shot learning、Prompt Based Learning、RAG
この分野の理解度をチェック!
最新シラバス対応のオリジナル模試で、本番レベルの問題に挑戦しませんか?
E資格オリジナル模試を見る →