Transformer
- 0.概要
- 1.Transformer
- キーワードまとめ
Contents
0.章の概要
Transformerは、自然言語処理や機械翻訳などの分野で革命をもたらした深層学習モデルです。このモデルは、自己注意機構(Self-Attention)を利用して、入力データの重要な部分に焦点を当てることができるため、文脈をより効果的に理解し、生成する能力を持っています。(CNNやRNNを一切使わず、並列計算が可能ため、学習速度が大幅に向上!!)Transformerの登場により、従来のリカレントニューラルネットワーク(RNN)や長短期記憶(LSTM)モデルに比べて、学習速度や性能が大幅に向上しました。
この章では、Transformerに使用されている主な技術を、1つずつ解説していきます。
1.Transformer
学習キーワード: Self-Attention、Scaled Dot-Product Attention、Source Target Attention、Masked Attention、Multi-Head Attention、Positional Encoding
Transformerの概要図
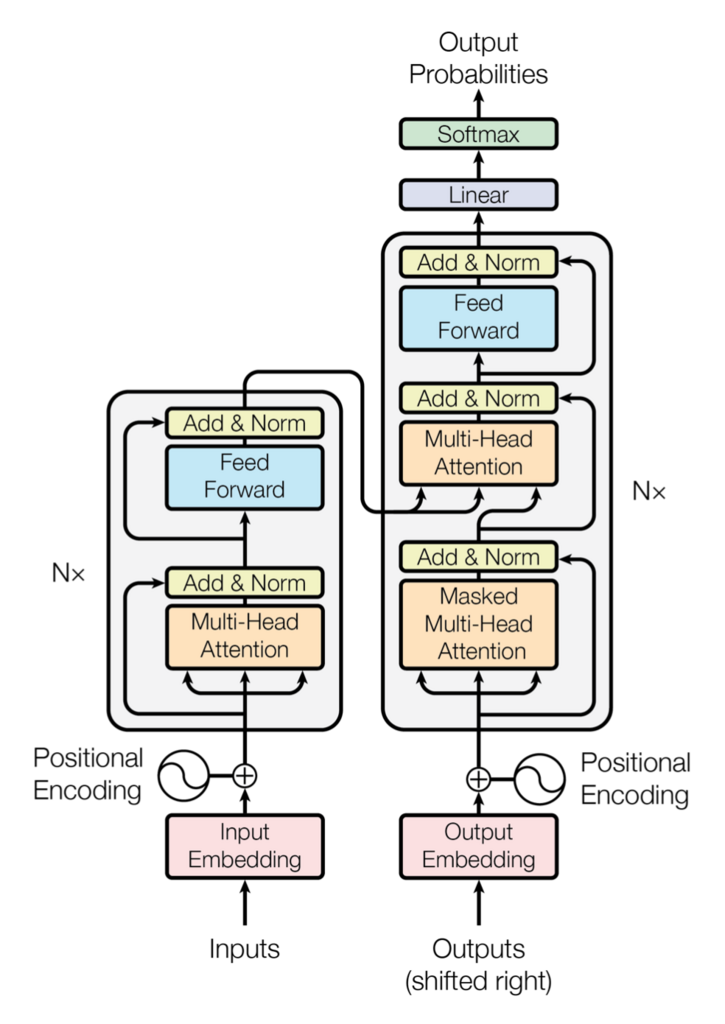
出典: Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017).
Attention is All You Need. Advances in Neural Information Processing Systems, 30.
上図は、CC BY 4.0ライセンスに基づき使用し、Creative Commons Attribution 4.0 International License に従います。
Scaled Dot-Product Attention
Scaled Dot-Product Attentionは、学習用のパラメータを持たない、入力された行列同士を単に演算するだけのネットワークです。QueryベクトルとKeyベクトルの配列からなる行列を入力に取り、Valueベクトルの加重平均を計算します。概要図にはScaled Dot-Product Attentionの記載がありませんが、下記図のように、Multi-Head Attention(詳細は後述)の中で使用されています。

出典: Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017).
Attention is All You Need. Advances in Neural Information Processing Systems, 30.
上図は、CC BY 4.0ライセンスに基づき使用し、一部赤枠で強調しています。Creative Commons Attribution 4.0 International License に従います。
Scaled Dot-Product Attentionの構造は下図の通りです。

出典: Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017).
Attention is All You Need. Advances in Neural Information Processing Systems, 30.
上図は、CC BY 4.0ライセンスに基づき使用しています。Creative Commons Attribution 4.0 International License に従います。
数式で表すと以下の通りです。
ここで、\( d \)はキーとクエリの次元数です。\( Q \)は入力データのクエリベクトル、\( K \)は入力データのキーベクトル、\( V \)は入力データの値ベクトルです。
step1. QueryベクトルとKeyベクトルの行列積の計算
これは、QueryベクトルとKeyベクトルの各要素間の相似度を計算することで、QueryベクトルがKeyベクトルにどれくらい似ているかを判断します。例えば、Queryベクトルが"I love you"、Keyベクトルが "I hate you" である場合、行列積の結果は "love"と"hate" の相似度が低く、"I"と"I"の相似度が高くなるイメージです。
step2. スケーリング
行列積の結果をスケーリングします。
行列積はベクトルの次元数が多いほど、出力結果が大きくなってしまいますが、ここでは純粋に類似度を知りたいだけですので、次元数(文章の長さ)の平方根で割ることで、出力結果を安定させます。
step3. ソフトマックス関数の適用
スケーリングした結果に対して、ソフトマックス関数を適用します。
ソフトマックス関数を用いて、ベクトルの各要素を0から1の範囲に正規化します。これにより、QueryベクトルとKeyベクトルの類似度が正規化され、加重平均の計算に適した形になります。
step4. Valueベクトルの加重平均
ソフトマックス関数の結果に対して、Valueベクトルを加重平均します。
つまり、Scaled Dot-Product Attentionは、QueryベクトルについてKeyベクトルと類似した情報を、Valueベクトルから抽出する手法であり、これにより予測する際に関連度の高い情報(単語)を使用できるようになります。
Source-Target AttentionとSelf-Attention
※Transformerでは、2種類のScaled Dot-Product Attentionが用いられています。KeyとValueをエンコーダの出力に、Queryをデコーダの出力に設定し、異なる文間の関係を学習するものをSource-Target Attention(またはEncoder-Decoder Attention)と呼びます。一方、Query, Key, Valueが同じ入力から生成され、同じ文内での依存関係を学習するものをSelf-Attentionと呼びます。(下図参考)

出典: Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017).
Attention is All You Need. Advances in Neural Information Processing Systems, 30.
上図は、CC BY 4.0ライセンスに基づき使用し、一部赤枠での強調、Attentionの種類を赤字黒枠で追記しています。Creative Commons Attribution 4.0 International License に従います。
Scaled Dot-Product Attentionの問題点として、学習パラメータがないため、多種多様なデータに対してはうまくいかないという点があります。それらを改善するために次に説明するSingle-Head Attentionが登場しました。
Single-Head Attention
Single-Head Attentionは、Scaled Dot-Product Attentionが学習しない欠点を補うために登場しました。具体的には下図のように、入力の直前に学習用のパラメータを持つネットワーク(Linear層)を追加します。

Single-Head Attentionは、入力の情報を1つの視点(重みベクトル)からしか捉えられないため、情報の多様な側面を捉えることが難しいという欠点があります。特に自然言語処理のような複雑なタスクでは、文脈や関係性を複数の観点から捉えることが重要であるため、次に説明するMulti-Head Attentionが登場しました。
Multi-Head Attention
Multi-Head Attentionは、各層が入力情報を多様な観点から同時に処理するために登場したメカニズムです。この仕組みにより、単一の視点だけでなく、複数の視点から文脈や関係性を効果的に学習することが可能となっています。
Multi-Head Attentionの構造は下図の通りです。

出典: Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017).
Attention is All You Need. Advances in Neural Information Processing Systems, 30.
上図は、CC BY 4.0ライセンスに基づき使用しています。Creative Commons Attribution 4.0 International License に従います。
- Queryベクトル、Keyベクトル、Valueベクトルをそれぞれ複数のヘッドに分割します。
- 各ヘッドでScaled Dot-Product Attentionを計算します。
- 各ヘッドの計算結果を結合します(concat)。
- Linear層に通して、最終的な出力を得ます。
数式で表すと以下の通りです。
- \( h \)はヘッドの数を表します。
- \( W^O \)は出力の重み行列を表します。
- \( head_h \)は各ヘッドのアテンションの結果を表します。
- \( QW^Q_h \), \( KW^K_h \), \( VW^V_h \)は各ヘッドでのクエリ、キー、値の変換結果を表します。
- \( Q \), \( K \), \( V \)は、それぞれクエリ、キー、値のベクトルを表します。
Transformerにおけるエンコーダーでは、\( Q \), \( K \), \( V \)は同じ埋め込みベクトルを使用(Self-Attention)し、デコーダーでは、\( Q \)は出力の埋め込みベクトル、\( K \)と\( V \)は入力の埋め込みベクトルを使用(Source-Target Attention)しています。
※Transformerの原論文では8つのSingle-Head Attentionが並列された構成になっています。
Masked Attention

出典: Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017).
Attention is All You Need. Advances in Neural Information Processing Systems, 30.
上図は、CC BY 4.0ライセンスに基づき使用し、一部赤枠で強調しています。Creative Commons Attribution 4.0 International License に従います。
通常のSelf-Attentionでは、すべての単語が互いに依存関係を参照できます。しかし、デコーダー部分では、出力文(ターゲット文)を順次生成する際に、まだ生成されていない「未来の単語」を参照してしまうと、答えを見ながら回答するようなカンニング状態になります。Masked Attention(概要図で言うMasked Multi-Head Attention)は、これを防ぎ、生成の順序性を保つために使われます。
要するに、Masked Attentionでは、Self-Attentionのスコア計算時にマスキング処理を施し、「まだ生成されていない未来の単語」を参照できないようにします。
具体的には三角行列を用いて、対角線の上側(未来の単語)を-∞に設定し、注意を向けないよう処理しています。

Positional Encoding

出典: Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017).
Attention is All You Need. Advances in Neural Information Processing Systems, 30.
上図は、CC BY 4.0ライセンスに基づき使用し、一部赤枠で強調しています。Creative Commons Attribution 4.0 International License に従います。
Positional Encoding(位置エンコーディング)は、Transformerモデルにおいて「単語の順序情報」を付加するために使用される技術です。TransformerではSelf-Attentionを用いて単語同士の関係を学習しますが、Attentionメカニズム自体には順序の概念がありません(順序概念を犠牲にし、並列計算を可能にしている)。そのため、Positional Encodingによって、入力シーケンス内の単語の順序情報を付与します。
Positional Encodingでは、各単語の位置に基づいて特定の値が生成され、それが埋め込み(embedding)ベクトルに加えられます。一般的に、以下のような正弦波と余弦波の関数を使って計算します。
ここで、\( PE(pos,2i) \) は位置 \( pos \) で偶数インデックスの値を示し、\( PE(pos,2i+1) \) は奇数インデックスの値です。\( d \) は埋め込みベクトルの次元数を示し、\( i \) はその次元における位置を示します。10000はハイパーパラメータで変更可能な値です。このように位置エンコーディングが生成されることで、単語の位置によって異なる周期で変化する値が生成され、順序情報が含まれます。
※三角関数を導入した理由
三角関数を使うことで、任意の長さの入力に対しても値が-1~1の範囲に収まるようにしています(長文になるほど、加える値が大きくなるのを防いでいる)。
※10000で割る理由
三角関数は周期的に同じ値を繰り返すため、長文になると同じ位置情報を加えることになってしまいます。10000で割ることで周期が大きくなるため、同じ値が繰り返されることを防げます。
※奇数偶数で別の関数を使う理由
上記で周期を大きくしたことで、小さい入力の差(例えば、1文字目と2文字目の差)が反映されにくくなりますので、奇数と偶数で別の関数を使うことで、その影響を防いでいます。
Transformerを構成するその他のパーツ
- Input(Output) Embedding:入力データをベクトルに変換するプロセス。これにより、単語をベクトルとして扱える。
- Feed Forward:全結合層(dense layer)を含むネットワークで、入力ベクトルを変換して出力ベクトルを生成する。Transformerでは2層のネットワークを使用している。
- Add & Norm:残差学習(Residual Connection)とLayer Normalizationを併用して、入力ベクトルと出力ベクトルを足し合わせ、正規化する。
関連用語の補足
- Layer Normalization:バッチサイズに対してデータの分布が偏ってしまうのを防ぐために、ミニバッチ内のデータの平均と分散を計算し、それを基に正規化する。
- Residual Connection:入力ベクトルと出力ベクトルを足し合わせることで、ネットワークの表現力を高める。
- Positional Embedding:Positional Encodingと異なり、学習用のパラメータを持つ。
キーワードまとめ
Self-Attention、Scaled Dot-Product Attention、Source Target Attention、Masked Attention、Multi-Head Attention、Positional Encoding
この分野の理解度をチェック!
最新シラバス対応のオリジナル模試で、本番レベルの問題に挑戦しませんか?
E資格オリジナル模試を見る →