画像認識
0.章の概要
画像認識とは、ニューラルネットワークを用いて画像内の物体やパターンを特定・分類する技術を指します。この章では、画像認識分野で重要な、深層学習を用いた主要なアーキテクチャであるResNet、WideResNet、そして最新のVision Transformerについて詳しく解説します。これらの技術は、医療画像診断、顔認識、自動運転車の視覚システム、さらには監視カメラによる異常検知など、さまざまな実世界のアプリケーションで活用されています。
1.ResNet, WideResNet
学習キーワード: 残差接続(skip-connection)、ボトルネック構造、Residual Block
概要
ResNet(Residual Network)とWideResNet(Wide Residual Network)は、ディープラーニングにおける非常に深いネットワークを効率的に学習するためのアーキテクチャで、2015年のILSVRCでの優勝モデルです。
ResNetは「残差接続(skip-connection)」という特殊な構造を採用しており、深い層での学習の安定性とパフォーマンス向上を実現しています。一方でWideResNetは、ResNetの改善版として、ネットワークの「幅」を増やすことで効率的な学習を目指しています。
ResNet
ResNetの最も重要な特徴は「残差接続(skip-connection)」の導入です。通常、深いニューラルネットワークは層を通過するごとに勾配が減衰してしまう「勾配消失問題」に直面しますが、ResNetでは残差接続により152層という深いネットワークでも勾配消失せずに学習することが可能になりました。
以下、ResNetの概要図です。
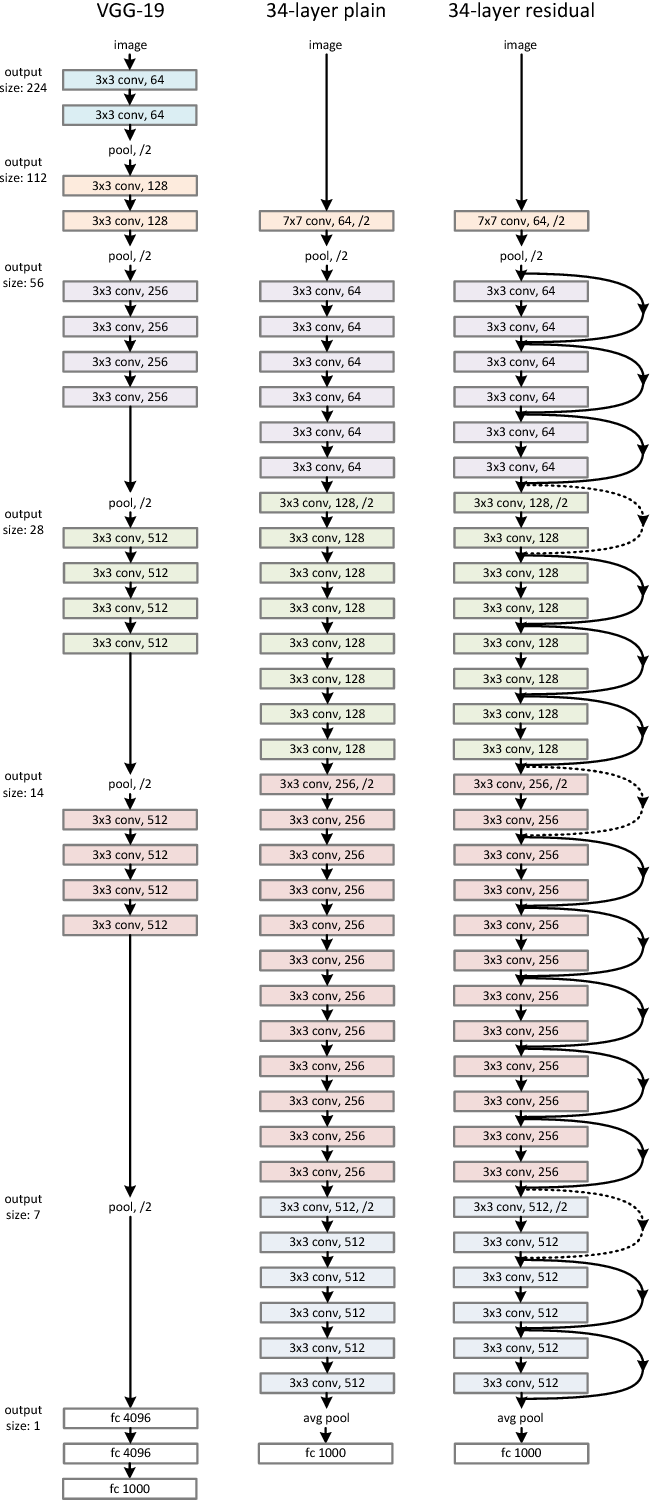
出典: He, K., Zhang, X., Ren, S., & Sun, J. (2016).Deep Residual Learning for Image Recognition.
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770-778.
https://doi.org/10.1109/CVPR.2016.90 本図は教育目的で引用しています。
残差接続では、ある層の出力にその層への入力を直接加える形で出力を生成します。これにより、ネットワークが出力に対して入力の「差分」、すなわち「残差」を学習する形になり、深い層まで勾配が伝わりやすくなります。この手法は、特に深いネットワークにおいて学習の安定性を向上させる効果があります。
残差接続は次のように表されます。
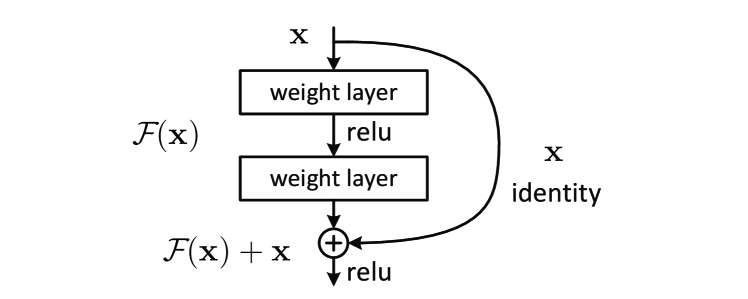
出典: He, K., Zhang, X., Ren, S., & Sun, J. (2016).Deep Residual Learning for Image Recognition.
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770-778.
https://doi.org/10.1109/CVPR.2016.90 本図は教育目的で引用しています。
ここで、\( x \) は入力、\(\mathcal{F}(x)\) はResidual Block内部の学習対象の関数(通常は畳み込み層を含む2~3層のサブネットワーク)、\( y \) は出力です。ネットワークはこの「残差」部分 \(\mathcal{F}(x)\) を学習し、\(x\) をそのまま維持することで、より安定した学習を可能にしています。(変換が必要ない場合は \(\mathcal{F}(x)\) の重みを0 にし、変換が求められる場合は差分を学習しやすくなります。)
※残差接続を含むブロックのことを残差ブロック(Residual Block)と言います。
※残差ブロックが勾配消失を改善する理由
残差ブロックが勾配消失を改善した理由は、逆伝播時の計算式を考えれば理解できます。
まず、残差ブロックの出力についての数式を再度示します。
ここで、\( x \) は入力、\(\mathcal{F}(x)\) はResidual Block内部の学習対象の関数、\( y \) は出力となり、誤差逆伝播の際に勾配は次のように計算されます。

上記式は、誤差逆伝播の過程で、残差ブロックの入力 \(x\) に対する誤差の勾配がどのように計算されるかを示しています。ここで、\(\frac{\partial L}{\partial y}\) は、残差ブロックの出力 \(y\) に対する誤差の勾配です。
残差ブロックでは、出力 \(y\) が入力 \(x\) と残差 \(\mathcal{F}(x)\) の和で構成されるため、勾配が減衰する問題が解決されます。式を見ても明らかように、\(\frac{\partial \mathcal{F}(x)}{\partial x}\) が小さくても、\(\frac{\partial L}{\partial x}\) は流れてきた勾配の \(\frac{\partial L}{\partial y}\) に近づくだけで、勾配消失が小さくなることを防ぐことができます。
ボトルネック構造
残差ブロックの種類には、Plane構造とボトルネック構造がありますが、ResNet-152では深い層数でも効率的に学習ができるよう「ボトルネック構造」が採用されています。このボトルネック構造は、次の3つの段階で構成されます:
- 1x1 畳み込み:次元削減を行い、チャンネル数を一時的に減らすことで計算量を減らす
- 3x3 畳み込み:空間的な特徴抽出を行うメインの畳み込み処理
- 1x1 畳み込み:再びチャンネル数を元に戻す
左図: Plane構造、右図:ボトルネック構造
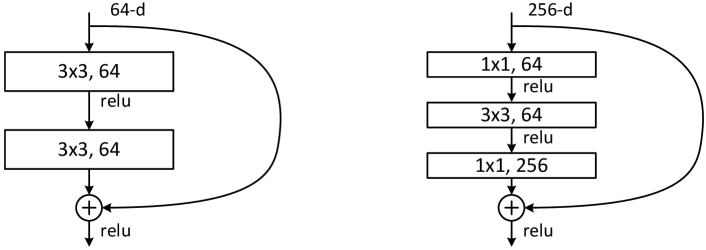
出典: He, K., Zhang, X., Ren, S., & Sun, J. (2016).Deep Residual Learning for Image Recognition.
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770-778.
https://doi.org/10.1109/CVPR.2016.90 本図は教育目的で引用しています。
左側の通常の残差ブロックと比較すると、ボトルネック構造の方がパラメーター数を抑えながら多層化を実現することができます。
WideResNet
WideResNetは、ResNetの改良版として登場しました。ResNetがネットワークを「深く」するのに対し、WideResNetは「幅を広げる」、すなわち各層のフィルタ数を増やすことで、より多くの特徴を学習し、効率的な学習を実現しました。
以下、WideResNetの概要図です。((a),(b)はResNet、(c),(d)はWideResNetのアーキテクチャを示します。)
出典: Zagoruyko, S., & Komodakis, N. (2016). Wide Residual Networks.
arXiv preprint arXiv:1605.07146.
https://arxiv.org/abs/1605.07146 本図は教育目的で引用しています。
WideResNetの特徴は以下の通りです。
- 従来のResNetに比べ50分の1の層数で、2倍高速に動作。
- 実験の結果、3x3の畳み込み層を2層、幅が10のものが良い結果を出している。
- Batch normalizationだけではなく、Dropout(0.3~0.4)を併用することで過学習を抑制。
関連用語の補足
- ILSVRC:ImageNet Large Scale Visual Recognition Challengeの略で、ImageNetという巨大なデータセットを使って、画像分類や物体検出、画像のセグメンテーションといったタスクの精度を競うコンペティションのこと。2012年から始まり、代表的な優勝・上位モデルとしてAlexNet、VGGNet、GoogLeNet、ResNet、DenseNetなどが挙げられる。
- 劣化問題:層を深くした際に、勾配消失問題が発生していないにも関わらず、モデルの精度が低下する現象。残差接続によってこの問題が改善されることがある。
2. Vision Transformer
学習キーワード: Shifted window、CLS token、Position embedding
概要
Vision Transformer(ViT)は、Transformerアーキテクチャを画像分類タスクに応用したモデルです(2020年にGoogleから発表)。自然言語処理で成功を収めたTransformerを画像データに適用することで、特に大規模データセットにおいて高いパフォーマンスを発揮しています。ViTは従来のCNNと異なり、Self-Attention機構を用いているため、画像全体の広範な関係性を捉えることが可能です。
Vision Transformerの構造
ViTの構造図とその処理の流れを以下に示します。
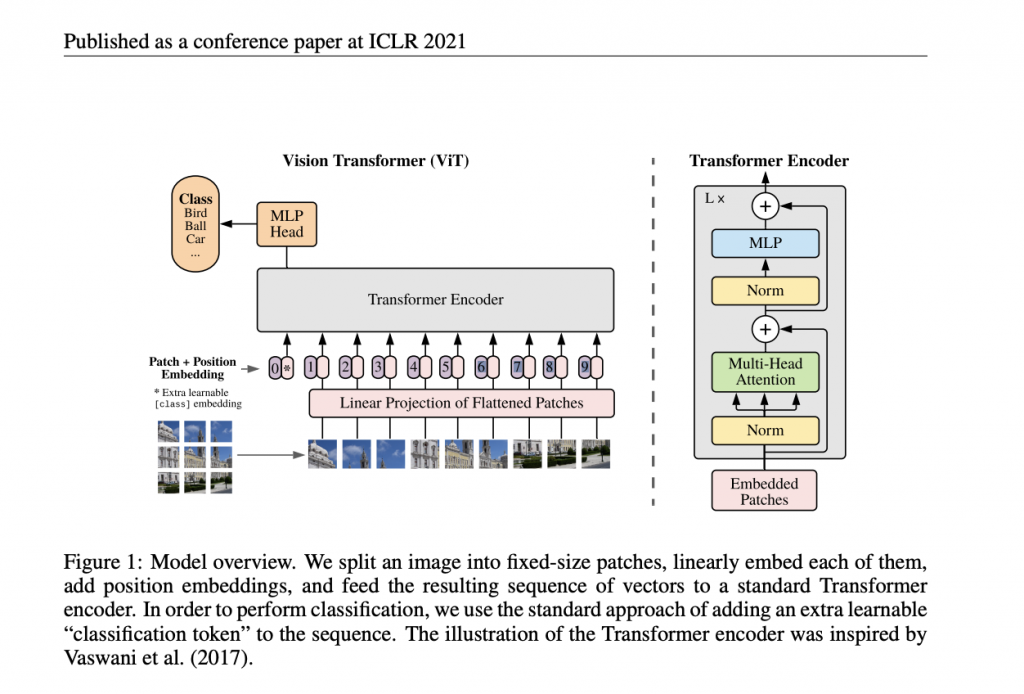
出典: Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., ... & Houlsby, N. (2020).
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. International Conference on Learning Representations (ICLR).
https://arxiv.org/abs/2010.11929
上図は、CC BY 4.0ライセンスに基づき使用し、Creative Commons Attribution 4.0 International License に従います。
- Patch分割:入力画像を小さなパッチに分割
- Patch Embedding:パッチを埋め込みベクトルに変換し、Transformerに入力可能な形式に変換
- Position Encoding:パッチの位置情報を埋め込みベクトルに追加し、順序情報を付与
- Transformer Encoder:Transformerエンコーダーを通じてパッチ間の関係性を学習し、特徴量を抽出
- MLP head:多層パーセプトロン(MLP)を通じて最終的な特徴量を生成し、画像分類タスクに適用
上記の各モジュールについて、以下で順を追って説明していきます。
Patch分割とPatch Embedding
まず、入力画像を固定サイズのパッチに分割、1次元ベクトルとしてフラット化し、固定長の埋め込みベクトルに変換されます。これにより、画像を単語(トークン)として扱うことが可能になり、Transformerモデルでの処理が行いやすくなります。

詳細な手順は以下の通りです。
画像の分割
入力画像は通常、サイズ \((H \times W \times C)\) のテンソル(例: 224×224×3のRGB画像)として扱われます。
\(H\), \(W\): 画像の高さと幅
\(C\): チャンネル数
この画像を固定サイズ \(P \times P\) のパッチに分割します。結果として、画像全体は次のように \(N\) 個のパッチに分解されます(各パッチは小さな画像領域を表します。):
フラット化と埋め込み
各パッチ(サイズ \(P \times P \times C\))を1次元ベクトルにフラット化します。これにより、各パッチは次元数が以下のようなベクトルになります:
フラット化されたベクトルに対して、学習可能な線形変換を適用し、埋め込み次元 \(D\) の固定長ベクトルに変換します。この埋め込み操作は次の式で表されます:
ここで:
- \(\mathbf{z}_i\): 埋め込みベクトル
- \(\text{Patch}_i\): \(i\) 番目のパッチ
- \(\mathbf{W}_E\): 学習可能な重み行列(サイズ \((P \times P \times C) \times D\))
- \(\mathbf{b}_E\): 学習可能なバイアスベクトル(サイズ \(D\))
この処理により、各パッチが固定長ベクトルに変換されます。
CLS Tokenの付与
CLSトークン (Classification Token) は、入力データ(画像や文章)全体の特徴を集約し、最終的な出力(クラスラベルや分類結果など)を生成するためのトークンです。このトークンは、Transformerの自己注意機構を通じて他のパッチトークンから情報を集約し、全体の文脈を考慮した分類を行う役割を果たします。
ここで、\(\mathbf{CLS}\)はCLS Tokenの埋め込みベクトルを表し、埋め込みベクトルの先頭に挿入されます。
CLS Tokenは、他のパッチトークンと同じ埋め込み次元を持つベクトルとして初期化され、学習可能なパラメータとして扱われます。自身はデータ(画像パッチや単語など)を直接持りませんが、Transformerの自己注意機構を通じて他のトークンから情報を集約します。
この処理の結果、画像全体がトークン列として扱えるようになり、Transformerに入力可能な形式となります。
Position Encoding
Positional Encoding(位置エンコーディング)は、Transformerモデルにおいて「トークンの順序情報」を付加するために使用される技術です。TransformerではSelf-Attentionを用いて単語同士の関係を学習しますが、Attentionメカニズム自体には順序の概念がありません(順序概念を犠牲にし、並列計算を可能にしている)。そのため、Positional Encodingによって、入力シーケンス内のトークンの順序情報を付与します。
Positional Encodingでは、各トークンの位置に基づいて特定の値が生成され、それが埋め込み(embedding)ベクトルに加えられます。一般的に、以下のような正弦波と余弦波の関数を使って計算します。
ここで、\( PE(pos,2i) \) は位置 \( pos \) で偶数インデックスの値を示し、\( PE(pos,2i+1) \) は奇数インデックスの値です。\( d \) は埋め込みベクトルの次元数を示し、\( i \) はその次元における位置を示します。10000はハイパーパラメータで変更可能な値です。このように位置エンコーディングが生成されることで、トークンの位置によって異なる周期で変化する値が生成され、順序情報が含まれます。
※三角関数を導入した理由
三角関数を使うことで、任意の長さの入力に対しても値が-1~1の範囲に収まるようにしています(長文になるほど、加える値が大きくなるのを防いでいる)。
※10000で割る理由
三角関数は周期的に同じ値を繰り返すため、長文になると同じ位置情報を加えることになってしまいます。10000で割ることで周期が大きくなるため、同じ値が繰り返されることを防げます。
※奇数偶数で別の関数を使う理由
上記で周期を大きくしたことで、小さい入力の差(例えば、1トークン目と2トークン目の差)が反映されにくくなりますので、奇数と偶数で別の関数を使うことで、その影響を防いでいます。
Transformer Encoder
画像データを埋め込みベクトルに変換した後、これらのベクトルはTransformer Encoderを通過して処理されます。Transformer Encoderは以下の3つの部分から構成されます:
- Multi-Head Attention:パッチ間の関係を捉えて、広範囲の特徴を学習します。
- MLPブロック:各パッチの特徴を変換し、非線形変換を行います。
- Layer Normalization(Norm):各層の出力に対して正規化を行い、学習の安定性を向上させる。
Multi-Head Attention
※しっかり理解したい方は、AttentionとTransformerの解説ページから理解することをおすすめします。
Attentionの解説はこちら
Transformerの解説はこちら
Multi-Head Attentionは、各層が入力情報を多様な観点から同時に処理するために登場したメカニズムです。この仕組みにより、単一の視点だけでなく、複数の視点から文脈や関係性を効果的に学習することが可能となっています。
Multi-Head Attentionの構造は下図の通りです。

出典: Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017).
Attention is All You Need. Advances in Neural Information Processing Systems, 30.
上図は、CC BY 4.0ライセンスに基づき使用しています。Creative Commons Attribution 4.0 International License に従います。
- Queryベクトル、Keyベクトル、Valueベクトルをそれぞれ複数のヘッドに分割します。
- 各ヘッドでScaled Dot-Product Attentionを計算します。
- 各ヘッドの計算結果を結合します(concat)。
- Linear層に通して、最終的な出力を得ます。
数式で表すと以下の通りです。
- \( h \)はヘッドの数を表します。
- \( W^O \)は出力の重み行列を表します。
- \( head_h \)は各ヘッドのアテンションの結果を表します。
- \( QW^Q_h \), \( KW^K_h \), \( VW^V_h \)は各ヘッドでのクエリ、キー、値の変換結果を表します。
- \( Q \), \( K \), \( V \)は、それぞれクエリ、キー、値のベクトルを表します。
ViTでは、\( Q \), \( K \), \( V \)は同じ埋め込みベクトルを使用(Self-Attention)しています。
MLPブロック

MLPブロックは、Linear(全結合層)、活性化関数(GELU関数)、Dropoutで構成されています。各パッチの特徴を変換し、非線形変換を行うことで、モデルがより複雑な特徴を学習することを可能にします。
Layer Normalization(Norm)
Layer Normalizationでは、レイヤーごとに各特徴量の分布を標準化することで、入力スケール変化に対するモデルの頑健性を高めます。主に、TransformerやRNNなどで用いられます。(CNNにはあまり適さないと言われています。)
正規化の種類や特徴については別ページで細かく解説しておりますので、参考にしてください。(正規化の解説はこちら)
MLP head
MLP headは、Transformer Encoderの出力をクラス予測に変換するために使用される分類層です。ここで、序盤に付与したCLS tokenが、Transformer Encoderを通じて学習された特徴量を代表し、MLP headの入力として使用されます。MLP headは、CLS tokenを入力として受け取り、画像のクラス予測を出力します。MLP headの構造は、一般的に複数の全結合層(Fully Connected層)で構成されており、各層は活性化関数を使用して非線形変換を行います。
関連用語の補足
- Shifted Window(Swin Transformer):Swin Transformer(2021年にMicrosoftから発表)で導入された手法です。 Shifted Windowは、画像を固定サイズのウィンドウに分割してウィンドウ内でSelf-Attentionを計算し、次のレイヤーではウィンドウの位置をシフトさせることで、隣接ウィンドウ間の情報交換を可能にする仕組みです。 通常のViTでは、全パッチ間でSelf-Attentionを計算するため計算量が画像サイズの二乗に比例しますが、Shifted Windowを用いることで、計算量はウィンドウサイズに依存する定数倍となり、画像全体のパッチ数に対して線形にスケールするため、高解像度画像への適用が容易になります。 物体検出やセマンティックセグメンテーションなど、画像分類以外の多様なビジョンタスクでも高い性能を発揮します。
-
GELU関数:GELU(Gaussian Error Linear Units)関数は、ニューラルネットワークの活性化関数の一つです。ReLU関数の代わりとして提案され、一部のモデルで使用されています。GELU関数は、入力が大きいほどReLU関数よりも大きな値を出力し、入力が小さいほどReLU関数よりも小さな値を出力します。これにより、GELU関数はReLU関数よりも広い範囲で非線形性を持ち、学習の速度を向上させることができます。

キーワードまとめ
残差接続(skip-connection)、ボトルネック構造、Residual Block、Shifted window、CLS token、Position embedding
この分野の理解度をチェック!
最新シラバス対応のオリジナル模試で、本番レベルの問題に挑戦しませんか?
E資格オリジナル模試を見る →