📋 この記事の目次
なぜ前処理が必要なのか?
前回の記事では、pydicomを使ってDICOM画像を読み込み、メタデータの取得やmatplotlibでの表示方法を学びました。しかし、読み込んだ画像をそのままAIモデルに入力しても、良い結果は得られません。
その理由は大きく3つあります。
- ピクセル値のスケールが不統一 ── DICOMの格納値はCT値(HU)に変換しないと意味のある数値にならない
- 画像サイズがバラバラ ── 撮影装置や施設によって512×512だったり256×256だったり異なる
- 学習データが不足する ── 医療画像は枚数が限られるため、データ拡張でバリエーションを増やす必要がある
前処理は、こうした「生のデータ」と「AIが学習できるデータ」の間を埋める作業です。ここを丁寧に設計できるかどうかが、モデルの精度を大きく左右します。
💡 この記事の前提
この記事は「PythonでDICOM画像を読み込んでみよう|pydicom入門」の続編です。pydicomの基本(dcmread()、pixel_array、RescaleSlope / RescaleIntercept)を理解していることを前提に進めます。まだの方は先にそちらをお読みください。
前処理パイプラインの全体像
CT画像の前処理は、以下の6つのステップで構成されます。順番が重要で、特にHU変換→ウィンドニング→正規化の順序を入れ替えると意味が変わってしまいます。
# 前処理パイプラインの流れ
#
# DICOM読み込み
# ↓
# Step 1: HU変換(ピクセル値 → CT値)
# ↓
# Step 2: ウィンドニング(表示範囲の限定)
# ↓
# Step 3: リサイズ(サイズ統一)
# ↓
# Step 4: 正規化(0〜1 にスケーリング)
# ↓
# Step 5: スライス選択・ボリューム構築
# ↓
# Step 6: データ拡張(回転・反転・ノイズ等)
# ↓
# AIモデルへ入力
では、各ステップをコード付きで見ていきましょう。まずは必要なライブラリをインポートします。
Python
from pydicom.data import get_testdata_file
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.family'] = 'MS Gothic'
import pydicom
import numpy as np
from scipy.ndimage import zoom, rotate
# サンプルDICOMファイルを読み込み
fpath = get_testdata_file("CT_small.dcm")
ds = pydicom.dcmread(fpath)
pixel_array = ds.pixel_array
Step 1:HU変換(ピクセル値→CT値)
DICOMファイルに格納されているピクセル値は「生の格納値」であり、そのままでは物理的な意味を持ちません。RescaleSlope と RescaleIntercept を使って CT値(HU: Hounsfield Unit) に変換します。
def convert_to_hu(ds):
"""ピクセル値をCT値(HU)に変換する"""
image = ds.pixel_array.astype(np.float64)
slope = float(getattr(ds, "RescaleSlope", 1))
intercept = float(getattr(ds, "RescaleIntercept", 0))
hu_image = image * slope + intercept
return hu_image
hu_image = convert_to_hu(ds)
print(f"HU範囲: {hu_image.min():.0f} 〜 {hu_image.max():.0f}")
💡 CT値の目安
CT値は組織の密度を表す指標です。空気が −1000 HU、水が 0 HU、骨が +1000 HU 前後です。この変換を行わないと、異なる装置で撮影した画像間でピクセル値の意味が一致せず、AIモデルの汎化性能が大幅に低下します。
Step 2:ウィンドニング(コントラスト調整)
CT値の範囲は −1000〜+3000 と非常に広いですが、AIが注目すべき組織は限られています。ウィンドニングで表示範囲を限定し、対象組織のコントラストを高めます。
Python
def apply_windowing(hu_image, center, width):
"""ウィンドニングを適用する"""
lower = center - width / 2
upper = center + width / 2
windowed = np.clip(hu_image, lower, upper)
return windowed
# 代表的なウィンドウ設定
windows = {
"肺野": (-600, 1500),
"軟部組織": (40, 400),
"骨": (300, 1500),
}
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
for ax, (name, (wc, ww)) in zip(axes, windows.items()):
windowed = apply_windowing(hu_image, wc, ww)
ax.imshow(windowed, cmap="gray")
ax.set_title(f"{name} (C={wc}, W={ww})")
ax.axis("off")
plt.tight_layout()
plt.show()
上のコードを実行すると、同じCT画像でもウィンドウ設定によって見え方が大きく変わることがわかります。
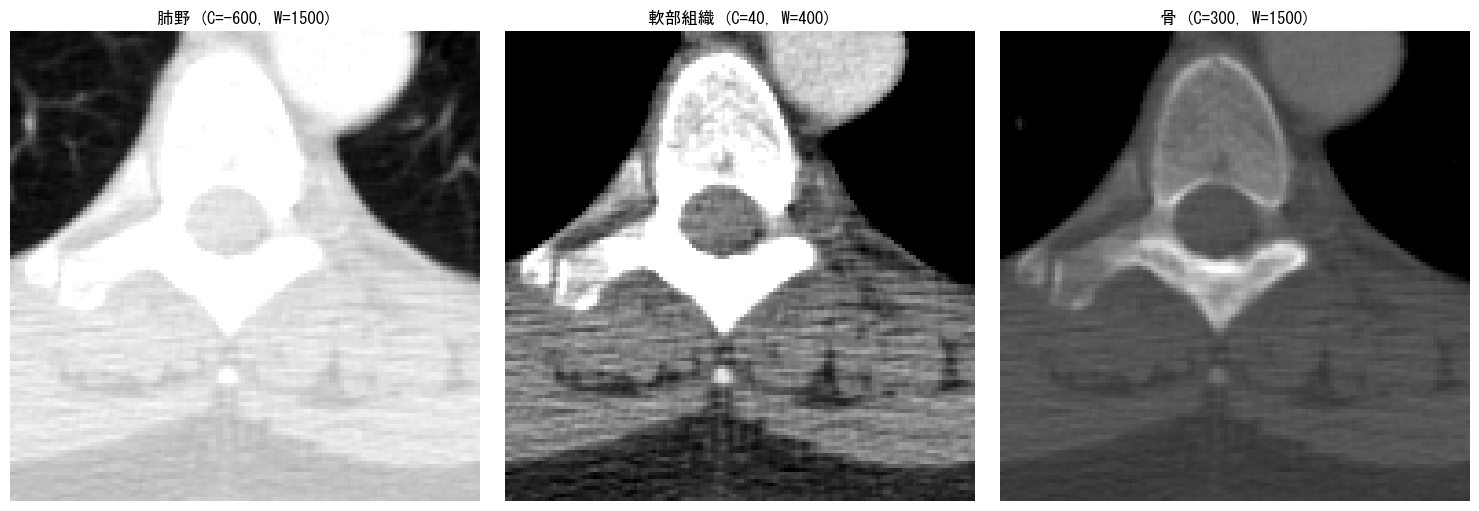
どのウィンドウ設定を選ぶかは、AIの目的によって変わります。肺結節の検出なら肺野ウィンドウ、肝臓の腫瘍検出なら軟部組織ウィンドウ、骨折検出なら骨ウィンドウを使います。
⚠ 複数ウィンドウの併用
近年の研究では、複数のウィンドウ設定を適用した画像を「マルチチャネル入力」(RGB画像の各チャネルに異なるウィンドウを割り当てる)としてCNNに入力する手法も使われています。例えば、肺野・軟部組織・骨の3種類をR/G/Bに割り当てると、1枚の画像で複数の組織情報を同時に活用できます。
Step 3:リサイズ(画像サイズの統一)
CT画像のサイズは撮影装置によって異なります(512×512が多いですが、256×256や1024×1024もあります)。AIモデルに入力するには、すべての画像を同じサイズに揃える必要があります。
Python
def resize_image(image, target_size=(256, 256)):
"""画像を指定サイズにリサイズする"""
h, w = image.shape
zoom_h = target_size[0] / h
zoom_w = target_size[1] / w
resized = zoom(image, (zoom_h, zoom_w), order=1)
return resized
# 軟部組織ウィンドウを適用してからリサイズ
windowed = apply_windowing(hu_image, center=40, width=400)
resized = resize_image(windowed, target_size=(256, 256))
print(f"リサイズ前: {windowed.shape} → リサイズ後: {resized.shape}")
💡 リサイズ時の補間方法
scipy.ndimage.zoom の order パラメータで補間方法を指定します。order=0 は最近傍補間(セグメンテーションマスクに使用)、order=1 は双線形補間(一般的な画像に使用)、order=3 は3次スプライン補間(より滑らかだが計算コストが高い)です。通常の画像には order=1 で十分です。
Step 4:正規化(0〜1スケーリング)
ニューラルネットワークでは、入力スケールを一定範囲に揃えることで学習が安定しやすくなります。ウィンドニング後の画像を 0〜1 にスケーリングしましょう。
Python
def normalize(image):
"""画像を 0〜1 に正規化する"""
img_min = image.min()
img_max = image.max()
if img_max - img_min == 0:
return np.zeros_like(image)
normalized = (image - img_min) / (img_max - img_min)
return normalized.astype(np.float32)
normalized = normalize(resized)
print(f"正規化後 → 最小: {normalized.min():.2f}, 最大: {normalized.max():.2f}")
ゼロ除算を防ぐガード処理(img_max - img_min == 0)を入れている点に注目してください。完全に均一な画像(全ピクセルが同じ値)が稀にあるため、この対策は必須です。
Step 5:スライス選択とボリューム構築
CT検査では1回のスキャンで数十〜数百枚のスライス画像が得られます。AIモデルに入力する際は、必要なスライスだけを選択するか、複数スライスを積み重ねて3Dボリュームを構築します。
Python
import os
import glob
def load_ct_volume(dicom_dir, target_size=(256, 256)):
"""ディレクトリ内のDICOMファイルをソートして3Dボリュームを構築する"""
dcm_files = glob.glob(os.path.join(dicom_dir, "*.dcm"))
slices = []
for f in dcm_files:
ds = pydicom.dcmread(f)
slices.append(ds)
# スライス位置(ImagePositionPatient[2])でソート
slices.sort(key=lambda s: float(s.ImagePositionPatient[2]))
volume = []
for s in slices:
hu = convert_to_hu(s)
windowed = apply_windowing(hu, center=40, width=400)
resized = resize_image(windowed, target_size)
normalized = normalize(resized)
volume.append(normalized)
return np.stack(volume, axis=0) # (スライス数, H, W)
# 使い方の例(実際のDICOMディレクトリを指定)
# volume = load_ct_volume("/path/to/dicom_series/")
# print(f"ボリューム形状: {volume.shape}")
# → 例: (120, 256, 256) = 120スライス × 256×256ピクセル
💡 スライスのソート順
ImagePositionPatient の第3成分(Z座標)でソートすることで、身体の上から下(頭側→足側)の順にスライスを並べられます。ファイル名の順番が必ずしもスライス順序と一致しないため、この処理は必須です。
Step 6:データ拡張(Data Augmentation)
医療画像は取得コストが高く、学習データの枚数が限られることが多いです。データ拡張は、既存の画像に変換を加えて学習データのバリエーションを人工的に増やすテクニックです。
Python
def augment_image(image, seed=None):
"""基本的なデータ拡張を適用する"""
rng = np.random.default_rng(seed)
augmented = image.copy()
# ランダム回転(-15° 〜 +15°)
angle = rng.uniform(-15, 15)
augmented = rotate(augmented, angle, reshape=False, order=1)
# ランダム水平反転(50%の確率)
if rng.random() > 0.5:
augmented = np.fliplr(augmented)
# ガウシアンノイズの付加
noise = rng.normal(0, 0.02, augmented.shape)
augmented = np.clip(augmented + noise, 0, 1)
return augmented.astype(np.float32)
# 拡張の例を可視化
fig, axes = plt.subplots(1, 4, figsize=(16, 4))
axes[0].imshow(normalized, cmap="gray")
axes[0].set_title("元画像")
for i in range(3):
aug = augment_image(normalized, seed=i)
axes[i+1].imshow(aug, cmap="gray")
axes[i+1].set_title(f"拡張 {i+1}")
for ax in axes:
ax.axis("off")
plt.tight_layout()
plt.show()
実行結果は以下のようになります。元画像に対して、回転・反転・ノイズがランダムに適用されたバリエーション画像が生成されます。
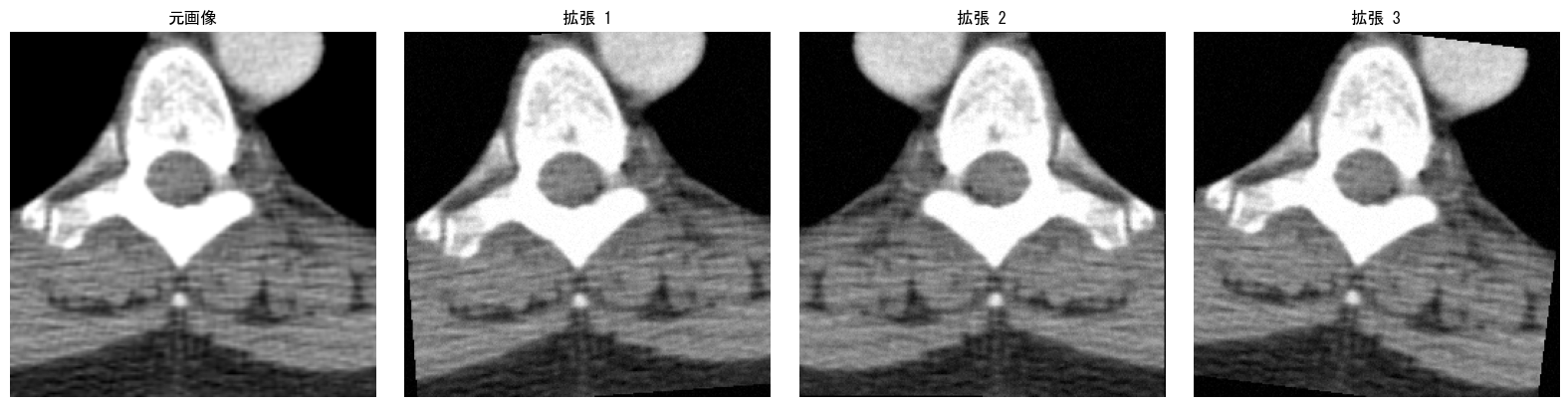
⚠ 医療画像でのデータ拡張の注意点
自然画像では色相変換や大幅なクロッピングも有効ですが、医療画像では注意が必要です。過度な回転は解剖学的にありえない画像を生成し、モデルに悪影響を与えます。一般的には、回転は ±15°程度、ノイズも控えめに設定します。また、セグメンテーションタスクではマスクにも同じ変換を適用する必要があります。
全処理をまとめたパイプライン関数
ここまでの処理をすべてまとめた、再利用可能なパイプライン関数を作りましょう。
Python
def preprocess_ct(ds, window_center=40, window_width=400,
target_size=(256, 256), augment=False):
"""CT画像の前処理パイプライン(1スライス分)"""
# Step 1: HU変換
hu_image = convert_to_hu(ds)
# Step 2: ウィンドニング
windowed = apply_windowing(hu_image, window_center, window_width)
# Step 3: リサイズ
resized = resize_image(windowed, target_size)
# Step 4: 正規化
normalized = normalize(resized)
# Step 6: データ拡張(学習時のみ)
if augment:
normalized = augment_image(normalized)
return normalized
# 使い方
result = preprocess_ct(ds, window_center=40, window_width=400, augment=False)
print(f"出力形状: {result.shape}, dtype: {result.dtype}")
print(f"値の範囲: {result.min():.3f} 〜 {result.max():.3f}")
この関数を使えば、DICOMファイル1枚を1行で前処理できます。学習時は augment=True、推論時は augment=False を指定すれば、用途に応じた切り替えも簡単です。
まとめ ── 次のステップへ
この記事では、CT画像をAIモデルに入力するための前処理パイプラインをPythonで構築しました。
- HU変換:
RescaleSlope / RescaleInterceptでピクセル値をCT値に変換 - ウィンドニング:目的の組織に合わせてコントラストを調整
- リサイズ:
scipy.ndimage.zoomで画像サイズを統一 - 正規化:0〜1 にスケーリングしてNNの学習効率を上げる
- スライス選択:
ImagePositionPatientでソートし3Dボリュームを構築 - データ拡張:回転・反転・ノイズで学習データを増やす(医療画像では控えめに)
前処理パイプラインが整ったら、次のステップは「CNNで画像分類モデルを学習させる」段階に入ります。PyTorchの Dataset クラスに今回のパイプラインを組み込めば、そのまま学習ループで使えます。
深層学習モデルの設計手法やCNNのアーキテクチャについて体系的に学びたい方は、E資格対策ページで解説しています。特にCNNの仕組みは医療画像AIの基盤技術なので、ぜひ合わせてチェックしてください。