様々な学習方法
- 0. 概要
- 1. 転移学習
- 2. 半教師あり学習と自己教師あり学習
- 3. 能動学習(Active Learning)
- 4. 距離学習(Metric Learning)
- 5. メタ学習(Meta Learning)
- キーワードまとめ
Contents
0.章の概要
この章では、様々な学習法について解説していきます。メインキーワードである転移学習、半教師あり学習、能動学習、距離学習、メタ学習といった手法は、現代のAI技術において非常に重要な役割を果たしています。これらの手法を理解することで、限られたデータを最大限に活用し、効率的に高精度なモデルを構築することが可能になります。あまり一般的な学習法に思えないかもしれませんが、これらの学習法をマスターすることは、AIスキルを向上させる上で必要不可欠になります。
1. 転移学習
学習キーワード: ファインチューニング、ドメイン適応 (domain adaptation)、ドメインシフト
概要
通常、高精度のAIモデルを開発するには、「多くのデータ」と「多くの学習時間」が必要になるため、コスト面等の理由から現実的ではないケースが多々あります。それらを解決する手法として、転移学習やファインチューニングが挙げられます。両者は共通して「事前学習済みのモデルを再利用し、効率的なモデル開発を行う」という特徴があり、目的に応じて使い分けられます。ここでは、転移学習とファインチューニングの違いに注目して見ていきましょう。
転移学習
転移学習は「事前学習済モデルは、数万~(LLMだと数十億~)の大規模なデータを学習した汎用モデルであり、幅広い領域のタスクに対応できる性能を持っているため、パラメータを微調整すれば、比較的簡単に特定の領域に特化したモデルができるはず」というモチベーションのもと行われます。(ファインチューニングにおいても同じです。)
具体的な手順は以下の通りです。
- 事前学習済みモデルの選択: 例: ImageNetで学習済みのResNetやVGGを利用。
- 出力層の変更: 元のモデルの出力層(分類層など)を新しいタスクに合わせて変更(例: クラス数を調整)。
- 重みの固定: 事前学習済みの層の重みを固定し、出力層のみを学習可能に設定。
- 学習: 新しいタスクに関連したデータを使用して、出力層をトレーニング。
- 評価と最適化: モデルの性能を評価し、必要に応じて出力層を調整。
ファインチューニング
ファインチューニングは、転移学習と異なり、出力層以外のパラメータも微調整します。
具体的な手順は以下の通りです。
- 事前学習済みモデルの選択: 転移学習と同様に、既存のモデルを選択。
- 出力層の変更: 新しいタスクに合わせて出力層を調整。
- 重みの初期化: モデル全体の重みを事前学習済みの値で初期化。
- 微調整可能な重みの設定: モデル全体の層を再学習可能に設定し、新しいタスクに適応させる。
- 学習: 既存の重みを大幅に崩さないよう、小さな学習率でモデル全体を再学習。
- 評価と最適化: モデルの性能を評価し、追加の調整(学習率やデータ量)を行う。
転移学習とファインチューニングの違い
転移学習とファインチューニングの最も大きな違いは、ネットワーク全体のパラメータを学習するかどうかです。
転移学習は、出力層のみを学習し、他の層のパラメータは固定します。これにより、学習に必要なデータセットのサイズが小さくて済みます。
ファインチューニングは、ネットワーク全体のパラメータを学習するため、より大きなデータセットと計算コストが必要になりますが、転移学習より高速で高精度のモデルが得られるケースが多いです。

ドメイン適応 (Domain Adaptation)
ドメインシフトは、Sourceドメイン(訓練データ)とTargetドメイン(テストデータ)のデータ分布が異なることを指します。例えば、A社のバナー画像で訓練されたモデルがB社の画像でテストされる場合、製品の識別精度が低下する可能性があります。これは転移学習においても言えることであり、事前学習済みモデルと新しく解きたいタスクの内容に大きな相違がある場合に問題となります。

ドメイン適応は、異なるデータセット間の特徴を類似させることで、SourceドメインとTargetドメインの間に存在する「ドメインシフト」を軽減し、モデルの性能を向上させることを目的とした技術です。
ドメイン適応の種類
ドメイン適応は、Targetデータのラベルの有無によって以下のように分類されます:
- 教師なしドメイン適応 : Sourceサンプルはラベル付きだが、Targetサンプルはラベルなし。
- 半教師ありドメイン適応: Targetサンプルの一部がラベル付き。
- 教師ありドメイン適応: SourceとTargetの全てのサンプルがラベル付き。
現実問題、訓練が終わるまでTargetデータへのアクセスがないことが前提ですので、教師なしドメイン適応の解決が重要になります。
関連用語の補足
- 蒸留: 学習済みのモデルの出力を用いて、軽量のモデルを作成する技術です。モデルを小さくすることで、計算リソースの消費を削減し、モデルの速度を向上させることができます。
2. 半教師あり学習と自己教師あり学習
学習キーワード: Self-Training、Co-Training、Contrastive learning
概要
半教師あり学習と自己教師あり学習は、ラベル付きデータが限られた状況下で、効率的に学習を進めるための手法です。半教師あり学習は、少量のラベル付きデータと大量のラベルなしデータを組み合わせて学習する手法で、擬似ラベルを活用したアプローチが特徴です。自己教師あり学習は、データ自身の情報を活用し、擬似ラベルを生成してラベルなしデータのみで学習を進めます。
半教師あり学習(Semi-Supervised Learning)
半教師あり学習(Semi-supervised Learning)は、少量のラベル付きデータ(正解データ)と大量のラベルなしデータを組み合わせて学習を行う手法です。完全な教師あり学習では、十分なラベル付きデータが必要ですが、ラベル付けにはコストや時間がかかるため、現実的には難しい場合があります。半教師あり学習は、ラベル付けされたデータの不足を補いながら、高精度なモデルを構築できるのが特徴です。
代表的な手法
半教師あり学習の代表的なブートストラップ法を2つご紹介します。
1. Self-Training- 概要: ラベル付きデータで学習したモデルを使い、ラベルなしデータに擬似ラベルを付けて再学習します。
- 手順:
- 初めに、ラベル付きデータのみを用いてモデルを訓練し、ラベルなしデータに対して予測を行います。
- 高い信頼度の予測結果をラベル付きデータとして追加し、再度モデルを訓練します。
- このプロセスを繰り返すことで、ラベルなしデータを活用しつつ、モデルを改善します。
- 利点: 擬似ラベルを繰り返し生成し、モデル精度を段階的に向上します。
- 概要: 2つ以上のモデルを別々の特徴セットで学習させ、相互に擬似ラベルを生成し合います。
- 手順:
- ラベルありデータを分割して、分類器1と分類器2でそれぞれ学習する。
- ラベルなしデータをそれぞれの分類器で分類する。
- 分類器1の確信度上位k個を分類器2のラベルありデータに追加し、分類器2の確信度上位k個を分類器1のラベルありデータに追加する。
- 上記の手順を繰り返すことで、モデルの精度を向上させます。
- 利点: 異なる視点から補完し合うことで、モデルの汎化性能を向上します。

自己教師あり学習(Self-Supervised Learning)
自己教師あり学習は、データ自身を使って擬似ラベルを生成し、大量のラベルなしデータで学習を行う手法です。
以前より、機械学習におけるラベリングの作業はとても労力のかかるものであり、AI開発を妨げる要因の1つでした。そこで、「ラベリング作業を行わずに、教師あり学習くらいの精度を担保したい」というモチベーションのもと注目された手法が自己教師あり学習です。
特に、画像分類や物体検出の分野では、教師あり学習と同等以上の性能を実現できています。
代表的な手法
1. Contrastive Learning- 概要: 類似したデータを近づけ、異なるデータを遠ざけることによって効果的な特徴表現を学習する手法です(主にエンコーダーでの学習の話)。
- 仕組み:
- アンカー(anchor)としてのデータと、そのデータに対する正例(positive example)を生成します。(正例はアンカーをデータ拡張(回転など)した画像であることが多い)
- アンカーに対する負例(negative example)を生成します。(アンカーとは全く別の画像であることが多い)
- アンカーと正例は近く、アンカーと負例は遠い埋め込みベクトルになるよう学習します。

- 代表モデル: SimCLR、MoCo。
LLMにおける自己教師あり学習
LLM(Large Language Model)における自己教師あり学習でもContrastive Learningが用いられています。以下にContrastive Learningを含めた、LLMにおける自己教師あり学習の例を示します。
1. Contrastive LearningLLMの中でもコントラスト学習が使われる場合があります。例えば、文章間の類似性を学習する場合:
- アンカー: 「私は本を読むのが好きだ。」
- 正例: 「私は小説を読むのが趣味だ。」(意味が類似している)。
- 負例: 「今日は天気がいいですね。」(意味が異なる)。
手法: モデルは正例ペアの埋め込みを近くに配置し、負例ペアを遠ざけるよう学習します。 具体的な応用例には、文検索(semantic search)や類似文検索があります。
2. マスク付き言語モデリング(Masked Language Modeling: MLM)
代表例: BERT
手法: 入力テキストの一部を「[MASK]」トークンに置き換え、その欠けた部分を予測する。
例:
入力:私は[MASK]を食べました。3. 自己回帰型モデリング(Autoregressive Modeling)
モデル出力:[MASK] = りんご
代表例: GPTシリーズ
手法: テキストを一文字(または一単語)ずつ予測する。
例:
入力:私はりんごを食べ
モデル出力: ました。
近年、自然言語処理AIが発達した背景には、上記のような自己教師あり学習を上手に用いていることが大きな要因になっています。
3. 能動学習(Active Learning)
学習キーワード: Uncertainty Sampling、Least Confident、Representative Sampling
概要
能動学習は、モデルが「学習効果が最も高い」と考えられるデータを選び、そのデータを人間がアノテーション(ラベル付け)することで効率的に学習を進める手法です。
主に以下のような状況で利用されます:
- ラベル付きデータの用意に高コストがかかる場合(例: 医療画像解析や自動運転データ。)
- ラベルなしデータは豊富に存在するが、ラベル付きデータが少ない場合。
能動学習の基本フロー
- 初期モデルの構築:
- Uncertainty Samplingの場合:少量のラベル付きデータで初期モデルを学習。
- Diversity Samplingの場合:初期モデルの学習は必要ではなく、ラベルなしデータに対してクラスタリングや距離計算を用いて分布や多様性を評価。
- ラベルなしデータの選択:モデルにとって学習効果が高いと推定されるデータを選択。
- Uncertainty Samplingの場合:モデルが予測に自信を持てないデータを優先的に選択。
- Diversity Samplingの場合:各クラスやデータ分布全体を代表するデータを選択。
- ラベル付け: 選択されたラベルなしデータを人間(または専門家)がアノテーション。
- 再学習: ラベル付きデータを増やしながらモデルを再学習。
- 繰り返し: 上記プロセスを繰り返す。
Uncertainty Sampling
Uncertainty Samplingは、モデルが予測に自信を持てないデータ(不確実性が高いデータ)を優先的に選択する手法です。 これにより、モデルが「苦手」とする領域を補強することができます。
主な手法:
-
Least Confident: モデルの予測確率が最も低いデータを選択します。数式で表すと以下のようになります。
\( argminP_{\theta} (y^{\ast} \mid x) \)ここで、\( \theta \) はモデルのパラメータ、\( P(y^{\ast} \mid x) \) は入力 \( x \) に対する予測確率、\( y^{\ast} \) は予測されたクラスラベルです。
要は、「最も確率の大きいラベルの確率が一番小さいデータを選択する」ということです。
例えば、A,B,Cの3分類問題に対して、入力データ1の予測結果が、(A,B,C)=(0.4,0.3,0.3)、入力データ2の予測結果が、(A,B,C)=(0.9,0.1,0.0)、入力データ3の予測結果が、(A,B,C)=(0.1.0.8,0.1)とします。
この場合、「最も確率の大きいラベルの確率が一番小さいデータ」である入力データ1が選択されます(最も確率の大きいラベルの確率が0.4)。 -
Margin Sampling: 上位2つのクラス間の予測確率の差が小さいデータを選択します。
例えば、A,B,Cの3分類問題に対して、入力データ1の予測結果が、(A,B,C)=(0.45,0.4,0.15)、入力データ2の予測結果が、(A,B,C)=(0.9,0.1,0.0)、入力データ3の予測結果が、(A,B,C)=(0.1,0.85,0.05)とします。
この場合、「上位2つのクラス間の予測確率の差が小さいデータ」である入力データ1が選択されます(上位2つのクラス間の予測確率の差が0.05)。 - Entropy Sampling: モデルの予測確率のエントロピー(情報量)が高いデータを選択します。 これは、モデルが「どのクラスも似たような確率で予測している」データを優先的に学習することを意味します。
Diversity Sampling
Diversity Samplingは実際のデータ分布を代表するようなデータをサンプリングする手法の事を指し、その代表的な手法としてRepresentative Samplingがよく用いられています。
特徴:
- データ全体をクラスタリングし、各クラスタの「代表的なデータ」を選択します。
- 特定のクラスや特徴に偏らず、全体のバランスを保つことを優先します。
Uncertainty Samplingには、モデルの決定境界付近のデータばかりが選ばれるため、データ全体の分布は反映できません。一方、Diversity Samplingでは、決定境界から離れたデータを取得し、各ラベルの分布を反映しますが、アノテーションコストが高くなることが課題です(現在は両者を組み合わせた手法も開発されています)。
4. 距離学習(Metric Learning)
学習キーワード: 表現学習、Siamese network、contrastive loss、Triplet loss、Triplet network
概要
距離学習は、埋め込み空間の特徴量の距離を学習し、データの表現を調整した後、「類似したものは近く、異なるものは遠くなるよう」にモデルを訓練する手法です。
主に、画像検索や顔認証、異常検知などで用いられています。
距離学習が必要な理由(CNNを用いた画像認識タスクに関して)
- CNNは、画像の特徴量を抽出する能力に優れているが、特徴量の距離を直接的に学習することができない。
- 少ない学習データで、良い性能が期待できる。
2サンプルによる比較
Siamese Networkの概要
Siamese Networkは、2つの同一のネットワークが並列して構成され、ネットワークから抽出した特徴量を使用し、類似度や距離を学習する手法を指します。
アルゴリズム
- 2つのネットワークに対となる画像を入力します(「同一の構造」と「共有された重み」を持ちます)。
- それぞれのネットワークから出力された特徴量を特徴空間に埋め込み、最適な距離 \(𝐷\) を算出します。
※距離 \(𝐷\) は決まった距離指標ではなく、ユークリッド距離、マハラノビス距離、Minkowski距離など様々な距離が適応されます。
損失関数-Contrastive Loss
Contrastive Lossは、同じクラスのデータペアは距離を縮め、異なるクラスのデータペアは距離を広げるように学習する損失関数です。
数式は以下の通りです。
ここで、\( y \) はペアが異なるクラスかどうかを示すラベル(\( y = 1 \) の場合、ペアは異なるクラス、\( y = 0 \) の場合、ペアは同じクラス)、\( m \) はマージン、\( d \) はペアの距離です。
第一項:\( (1 - y) \cdot \left( \frac{1}{2} d^2 \right) \) は、同じクラスのデータペアに対する損失です。ペアの距離 \( d \) が小さいほど、損失が小さくなります。これにより、同じクラスのデータペアは距離を縮めるように学習します。なお、異なるクラスの場合は0になります。
第二項:\( y \cdot \left( \frac{1}{2} \max(0, m - d)^2 \right) \) は、異なるクラスのデータペアに対する損失です。ペアの距離 \( d \) がマージン \( m \) 以上である場合、損失が小さくなります。これにより、異なるクラスのデータペアは距離を広げるように学習します。なお、同じクラスの場合は0になります。
課題
2データ間での比較では、注目する特徴によって、似ているか似ていないかの判断が難しいという課題があります。
※例えば、日本人とアメリカ人の特徴空間の距離を学習する際、「人間」というくくりでは近いが、「人種」というくくりでは遠くなるという矛盾が生じます。
この課題を解決するために、次に説明する「Triplet Network」が注目されました。
3サンプルによる比較
Triplet Networkの概要
Triplet Networkは、3つの入力データを使用して類似度を比較します。通常、Anchor(基準データ)、Positive(同じクラスのデータ)、Negative(異なるクラスのデータ)の3データを用います。
アルゴリズム
ベース(基準)となる画像(Anchor)に対して、似ている画像の距離を近くし、似ていない画像の距離を大きくするように学習を行います。ネットワークの数は3つに増えますが、Siamese Networkと同じく、「同一の構造」と「共有された重み」を持ちます。
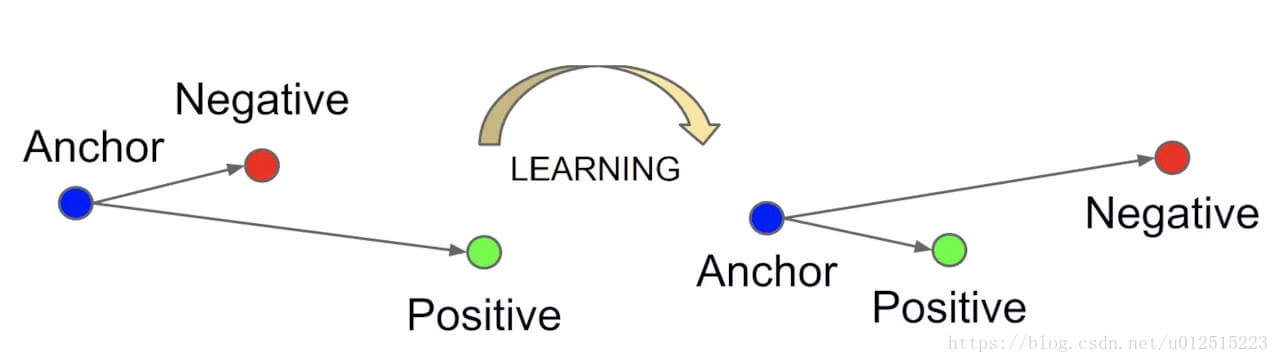
出典: Schroff, F., Kalenichenko, D., & Philbin, J. (2015). FaceNet: A Unified Embedding for Face Recognition and Clustering.
arXiv preprint arXiv:1503.03832.
https://arxiv.org/abs/1503.03832 本図は教育目的で引用しています。
損失関数-Triplet Loss
Triplet LossはAnchorとPositiveの距離がAnchorとNegativeの距離よりも小さくなるように学習する損失関数です。
数式は以下の通りです。
- \( d_p \) :AnchorとPositiveの距離(\( d_p = distance(f(x_a), f(x_p)) \))
- \( d_n \) :AnchorとNegativeの距離(\( d_n = distance(f(x_a), f(x_n)) \))
- \( g \) :ギャップパラメータ(マージン)
- \( f \) :CNNを表し、特徴量を抽出する関数
- \( x_a, x_p, x_n \) :Anchor、Positive、Negativeの各入力
※順調に学習が進むと、\((g+d_p)\)と\((d_n)\)が等しくなります。
※距離 \(D\) ではユークリッド距離(二乗ノルム)が用いられます。
関連用語の補足
- 表現学習:データから意味のある特徴や表現を自動的に学習する手法を指し、距離学習で「データ間の類似度を学習するための適切な特徴」を得る基盤ともなります。
5. メタ学習(Meta Learning)
学習キーワード: MAML、Model-Agnostic、メタ目的関数(meta-objective)
概要
メタ学習(Meta Learning)は、いわば「学習するための学習」であり、新しいタスクを少量のデータで効率的に学習できるモデルを構築する手法です。 通常の機械学習モデルは特定のタスクに対応するよう学習しますが、メタ学習では、複数のタスクを通じて「タスク間で共通する知識」を学びます。 この知識を活用することで、新しいタスクへの迅速な適応が可能になります。
初期値の獲得
MAML(Model-Agnostic Meta-Learning)
MAMLは、代表的なメタ学習手法の一つで、学習モデルの「良い初期値」を見つけることを目的とします。 モデルが新しいタスクに少数回の勾配降下(fine-tuning)で適応できるような初期値を学習するのですが、 Model-Agnostic(モデルに依存しない)という名称の通り、あらゆる微分可能なモデルで利用可能です。
MAMLの流れ
- 複数のタスクからデータを準備: 複数の異なるタスクを用意します。(例:タスクAは犬分類、タスクBは猫分類、タスクCは亀分類)
- 初期モデルの設定: 共通モデルのパラメータ \( \theta \) を初期化します。この初期値が、すべてのタスクに迅速に適応できるように学習されていきます。
-
タスクごとの最適化(内ループ): 各タスクは初期パラメータ \( \theta \) から学習を開始し、各タスクの損失関数 \( \mathcal{L}_{\mathcal{T}_i} \) を最小化するようにパラメータをSGDで更新します。パラメータ \( \theta_i' \) は以下の式で計算されます。
\[ \theta_i' = \theta - \alpha \nabla_{\theta} \mathcal{L}_{\mathcal{T}_i}(f_{\theta}) \]
- \( \theta \):初期パラメータ
- \( \mathcal{L}_{\mathcal{T}_i} \):タスク \( i \) の損失関数
- \( \alpha \):学習率
この段階で、タスクごとで最適化されたパラメータ \(\theta_i'\) が決まり、その時の損失 \( \mathcal{L}_{\mathcal{T}_i} \) も決まります。
-
メタ目的関数(Meta-Objective)の最適化(外ループ): 内ループで得られた、各タスクから算出された損失 \( \mathcal{L}_{\mathcal{T}_i} \) の和(メタ目的関数)が最小化するように、共通モデルのパラメータ \( \theta \) を調整する。( \(\theta_i'\) と \( \theta \) を混在しないように注意!)
\[ \min_{\theta} \sum_{\mathcal{T}_i \sim p(\mathcal{T})} \mathcal{L}_{\mathcal{T}_i}(f_{\theta_i'}) = \min_{\theta} \sum_{\mathcal{T}_i \sim p(\mathcal{T})} \mathcal{L}_{\mathcal{T}_i}(f_{\theta-\alpha\nabla_{\theta}\mathcal{L}_{\mathcal{T}_i}(f_{\theta})}) \]
- \( \theta \):モデルのパラメータ
- \( \mathcal{T}_i \):タスク \( i \)
- \( p(\mathcal{T}) \):タスクの分布
- \( \mathcal{L}_{\mathcal{T}_i} \):タスク \( i \) の損失関数
- \( f_{\theta} \):モデル関数
- \( \alpha \):学習率
- \( \nabla_{\theta} \):勾配
MAMLで学習した \(θ\) を他のタスクの初期値にすると、どのタスクでパラメータを更新(\(\theta_1^*\), \(\theta_2^*\), \(\theta_3^*\))しても効率的な学習が可能になります。(下図参考)
出典: Finn, C., Abbeel, P., & Levine, S. (2017). Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks.
arXiv preprint arXiv:1703.03400.
https://arxiv.org/abs/1703.03400 本図は教育目的で引用しています。
まとめとして、MAMLを使うと、学習した初期パラメータ \( \theta \) が、新しいタスクでも、少量のデータと数回の勾配降下だけで素早く適応できるようになります。
MAMLの課題
MAMLは各タスクごとの勾配計算と共通パラメータの勾配計算があり、計算量が膨大になります(2階微分)。その対策として、二次勾配以上の計算を省略した first-order MAML も提案がされています。
関連用語の補足
- メタ目的関数(Meta-Objective): 複数のタスクにおける損失関数の総和を最小化する目的関数。
- Few-shot Learning: 少数の例(ショット)から新しいタスクを学習する能力を指します。メタ学習の応用の一つで、MAMLもこの技術に基づいています。例えば、「1shot-5way」という表現は、5つのクラス(way)に対して各クラス1枚の画像(shot)を見て学習することを意味します。
キーワードまとめ
ファインチューニング、ドメイン適応 (domain adaptation)、ドメインシフト、Self-Training、Co-Training、Contrastive learning、Uncertainty Sampling、Least Confident、Representative Sampling、表現学習、Siamese network、contrastive loss、Triplet loss、Triplet network、MAML、Model-Agnostic、メタ目的関数(meta-objective)
この分野の理解度をチェック!
最新シラバス対応のオリジナル模試で、本番レベルの問題に挑戦しませんか?
E資格オリジナル模試を見る →