生成モデル
- 0. 概要
- 1. 識別モデルと生成モデル
- 2. オートエンコーダ
- 3. GAN
- キーワードまとめ
Contents
0.章の概要
この章では、生成モデルの基本概念、識別モデルとの違い、オートエンコーダやGANなどの主要な生成モデルの手法について解説します。画像生成AIがどのように進化していったかを、ポイントを押さえながら1つずつ理解していきましょう。
1. 識別モデルと生成モデル
学習キーワード: 識別モデル、自己回帰、生成モデル、拡散モデル、フローベース生成モデル
概要
識別モデルと生成モデルは、機械学習における2つの主要なモデルです。 識別モデルは、入力から出力を直接予測するタスクに特化し、分類や回帰などの問題に適用されます。 一方、生成モデルはデータの分布を学習し、新しいデータを生成する能力を持ちます。これにより、画像生成やテキスト生成などの創造的なタスクが可能になります。
識別モデルと生成モデルの比較
| 特徴 | 識別モデル(Discriminative Model) | 生成モデル(Generative Model) |
|---|---|---|
| 目的 | 入力データからクラスを予測する。 | データの分布を学習し、新しいデータを生成する。 |
| 学習対象 | 入力からクラスへの対応関係を直接学習。 | データの背後にある確率分布そのものを学習。 |
| 出力 | 入力データから予測されたクラス。 | データの分布から生成された新しいデータ(画像、テキスト、音声など)。 |
| 適用タスク |
|
|
| 代表的な手法 |
|
|
| 応用例 |
|
|
自己回帰(Autoregressive)モデル
自己回帰モデルは、データの生成をステップごとに行い、過去に生成した要素を条件として次の要素を順次予測・生成する手法です。 テキスト生成における代表例としてGPTシリーズ(GPT-nの解説はこちら)があり、前の単語(トークン)列を条件として次のトークンの確率分布を予測します。
自己回帰モデルの生成過程は以下の条件付き確率の積で表されます。
ここで、\( x_t \) は \( t \) 番目の要素(例: トークン)、\( T \) は系列の長さを表します。このように、各ステップで過去の情報(コンテキスト長の範囲内)を考慮して次の要素を予測するため、データの順序的な依存関係を精密にモデル化できます。
自己回帰モデルは、尤度を直接最大化できるため学習が安定しやすいという利点がありますが、推論(生成)プロセスにおいては各ステップが前の結果に依存する逐次処理となるため、並列化が難しく、長い文章を生成する際の速度(スループット)に課題があります。
拡散モデル
拡散モデルは、画像や音声などのデータを生成するモデルのことで、データをノイズで破壊してから再構築する独特なアプローチを使います。高品質なデータ生成が可能であり、画像生成や音声合成など、多くの分野で応用されています。また、学習の安定性も高く、従来の生成モデル(例: GAN)では問題となっていた「モード崩壊」(特定の種類のデータしか生成できない現象)が少なくなりました。
拡散モデルの仕組み
拡散モデルは、拡散過程(ノイズの付加)と逆拡散過程(ノイズの除去)という2つのプロセスで構成されています。
- 拡散過程:元のデータ(例えば画像)に少しずつノイズを加えていきます。何回もノイズを加えることで、最終的には完全なガウスノイズ(白い粒のようなもの)に変わります。例えるなら、元の画像を「徐々にぼかしていく」ようなイメージです。また、計算したノイズを元画像に追加していくだけのため、ステップごとの学習が不要でアーキテクチャは割とシンプルになります。
- 逆拡散過程:ノイズまみれの状態から、作成したネットワーク構造で、逆方向にノイズを少しずつ取り除きます。このプロセスを繰り返すことで、元のデータ(または新しいデータ)を生成します。例えるなら、ぼやけた写真を「少しずつ鮮明に戻す」イメージです。
拡散モデルの課題
拡散モデルは、計算コストが高いという課題があります。ノイズ除去のプロセスは多段階で行われるため、計算量が非常に多く、生成に時間がかかります。
フローベース生成モデル
フローベース生成モデルは、尤度を直接計算し、その尤度を最大化することで学習可能な生成モデルになります。特徴的なのは、可逆的な変換を利用してデータと単純な確率分布(例: ガウス分布)を結びつける点です。この可逆性により、データ生成だけでなく、確率密度の計算も可能となります。
フローベース生成モデルの仕組み
フローベース生成モデルは、以下のプロセスで構成されています。
1. 初期化
- 単純な確率分布からランダムなノイズデータを生成。
2. 変換の適用
- ランダムノイズに対して、一連の可逆的な変換を適用。この変換はニューラルネットワークによって構築され、ノイズデータを目標とするデータ分布(生成したい画像など)に徐々に変形。
この変換は段階的に行われ、各ステップでデータの構造が洗練されていく。
3. データ生成
- ノイズデータが段階的に変形された後、出力されるデータは目標とするデータ分布に従うものとなり、新しい画像や音声データとして出力。
フローベース生成モデルの課題
フローベース生成モデルは、複雑な変換を多段階で行うため、計算コストが高くなります。
関連用語の補足
- DALL-E:OpenAIが開発した、テキストから画像を生成するAIモデル。テキストの文章を入力すると、文章の内容に基づいて画像を生成することができる。
- Imagen:Googleが開発した、テキストから画像を生成するAIモデル。DALL-Eと同じくテキストの文章を入力すると、文章の内容に基づいて画像を生成することができる。
2. オートエンコーダ
学習キーワード: Denoising autoencoder、VAE、Reparameterization Trick、変分下限
概要
オートエンコーダは、入力データを効率的に圧縮して低次元化し、その後、元のデータに復元するように設計されたニューラルネットワークです。 「エンコーダ」と「デコーダ」の2つの主要な部分から構成され、データ構造やパターンを学習するのに有効とされています。

オートエンコーダ
構造と基本動作
- エンコーダ:入力データを受け取り、低次元の潜在変数(潜在空間)に変換(元のデータの主要な特徴や情報を維持しつつ、低次元化)します。
- デコーダ:潜在変数を使用して元のデータを復元しながら、元のデータと近いデータを生成するように学習されます。
- 損失関数:入力と復元された出力の間の差を最小化するように学習します。
オートエンコーダの応用例の1つに、画像や音声などのデータからのノイズ除去があります。このように、入力データに意図的にノイズを加えて、それを除去するように学習させることでデータのノイズ耐性を高める手法を「Denoising Autoencoder(デノイジングオートエンコーダ)」といいます。
VAE(Variational Autoencoder)
VAEはオートエンコーダの一種で、変分オートエンコーダとも呼ばれます。
オートエンコーダの潜在変数 \(z\) をガウス分布(\(z \sim \mathcal{N}(0,1)\)を仮定)として考え、確率的ゆらぎに従ってデータ生成ができるよう設計されました。通常のオートエンコーダーだと、潜在変数にデータを押し込みますが、その構造がどうなっているかは不明です。その点、VAEは、潜在変数を確率分布という構造に押し込めていることが大きな違いです。
構造と基本動作
Encoderでは、下図のように、入力データ(画像)から潜在変数 \(𝑧\) の平均と分散(主に2~50次元程度)を出力します。

Decoderでは、平均0、分散1の正規分布(多次元)から潜在変数 \(𝑧\) をランダムサンプリングし、出力データを生成します。(学習時は、入力データ(画像)と同じになるように調整される。)

入力データ(画像など)を数~数十次元に次元圧縮することがポイントです!その後は、ガウス分布(平均0、分散1)に従う \(ε\) をランダムで選び、\(μ\) と \(σ\) を用いて \(z\) に変換し、Decoderに通すだけで新しい画像が生成されます。
VAEの損失関数
VAEは、変分下界を最大化することで学習します:
- \(B(\theta, \Phi)\): 変分下界
- \(\theta\): パラメータ
- \(\Phi\): 潜在変数の分布
- \(q_{\Phi}(z|x)\): 潜在変数の条件付き分布
- \(p_{\theta}(x,y)\): データの分布
- \(p_{\Phi}(z|x)\): 潜在変数の事前分布
- \(D_{KL}(q_{\Phi}(z|x) \| p(z))\): KLダイバージェンス
\(E q_{\Phi(z|x)} [\ln p_{\theta}(x|z)] \) : RecnstructionError(復元誤差)と呼ばれ、\(𝑧\) を入力して出力された \(𝑥\) の分布の期待値を指します。(最大化が目標)
\(D_{KL}(q_{\Phi}(z|x) \| p(z))\) :RegularizationParameter(正則化項)と呼ばれ、\(𝑞(𝑧|𝑥)\) つまり \(𝑥\) を入力して出力(エンコード)した際の平均 \(μ\) 分散 \(σ\) の正規分布と、\(p_{\theta}\) つまり平均 0 分散 1 の正規分布の近似度を指します。(最小化が目標)
学習済みの平均 \(μ\) 分散 \(σ\) より、正規分布に従う \(𝑧\) をサンプリングし、Decoderに通すことで、新しい画像を生成できるようになります。
※Decoderでは、潜在変数 \(𝑧\) をランダムサンプリングして画像生成するため、誤差逆伝播が出来ないという問題がありました。以下では、それを解決した手法である「Reparameterization Trick」を解説します。
Reparameterization Trick(再パラメータ化トリック)
潜在変数を確率的な分布のパラメータに基づいてサンプリングし、勾配を計算できるようにします。具体的には、以下のように、潜在変数 \( z \) を、平均 \(\mu\) と標準偏差 \(\sigma\) を用いて、次のようにサンプリングします。
ここで、\(\epsilon\) は標準正規分布からサンプリングされるノイズです。
このように、ランダムでサンプリングしていた部分を数式で表現することで、逆伝播が可能になります。

関連用語の補足
- VQ-VAE:VAEの変種で、量子化された潜在変数を使用して、より効率的なデータ圧縮と復元を行う。
3. GAN
学習キーワード: 生成器ネットワーク、識別器ネットワーク、モード崩壊 (mode collapse)、Wasserstein GAN、DCGAN、 Conditional GAN、CycleGAN
概要
GAN(Generative Adversarial Network)は、2つのニューラルネットワーク(生成器と識別器)を組み合わせて、「本物そっくりなデータ」を生成するための機械学習モデルです。 これらのネットワークは互いに競争しながら学習を進め、生成器が徐々に識別器を騙せるようなデータを生成できるようになります。 GANは多数の派生形が出ていますが、ここでは、基本的なGANと代表的な派生モデルをいくつか解説していきます。
以下にGANで生成された画像を示します。

出典: Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., ... & Bengio, Y. (2014). Generative Adversarial Networks.
arXiv preprint arXiv:1406.2661.
https://arxiv.org/abs/1406.2661 本図は教育目的で引用しています。
基本的なGAN
基本構造
GANはGeneratorとDiscriminatorの2つのネットワークを用いて学習を進めていきます。
- 生成器ネットワーク(Generator): ランダムノイズを入力として、本物そっくりのデータを生成します。目標は、識別器に「本物」と判断させるデータを生成することです。
- 識別器ネットワーク(Discriminator): 本物のデータと生成されたデータを見分ける役割を担います。目標は、「本物」と「偽物」を正確に分類することです。
基本動作
GANの全体の処理の流れは以下の通りです。
- Generator:ランダムノイズ(例えば多次元正規分布) \(𝑧\) を入力として、偽のデータ fake-img を生成。
- Discriminator:偽物のデータ fake-img と本物のデータ real-img を入力とし、本物か偽物かを判定する2クラス分類を行う。

次に、詳細な学習ステップを示します。
- Generatorのパラメータを固定した状態でDiscriminatorを学習する。←先にDiscriminatorの学習から行うのがポイント!!
- ランダム生成したノイズベクトル \(\mathbf{z}\) をGeneratorに入力し、fake-img \(\mathbf{G}(\mathbf{z})\) を生成。
- 生成したfake-imgに偽物ラベル0を付加し、real-imgに本物ラベル1を付加する。
- fake-imgとreal-imgをDiscriminatorに入力して識別(0 or 1)を行い、Discriminatorのパラメータを更新していく。(Discriminatorのみを学習させるので、Generatorの重みは固定。正しく識別することを目標とするため、出力 \(D(G(z))\) を0に近づけることを目標。)
- Discriminatorのパラメータを固定した状態でGeneratorを学習する。
- ランダム生成したノイズベクトル \(\mathbf{z}\) をGeneratorに入力し、fake-img \(\mathbf{G}(\mathbf{z})\) を生成する。
- 生成したfake-imgに本物ラベル1を付加する。(このStepではGeneratorがDiscriminatorを騙すよう学習するため、結果が本物と判定されるようにlossを小さくしていく。)
- fake-imgをDiscriminatorに入力して識別(0 or 1)を行い、Generatorのパラメータを更新していく。(Generatorのみを学習させるので、Discriminatorの重みは固定。Discriminatorが本物と間違うような画像を生成することが目標であるため、出力 \(D(G(x))\) を1に近づけることを目標。)
1と2のステップを交互に繰り返すことで、Generatorは本物と見分けがつかないくらいの画像を生成できるようになります。
損失関数
損失関数は、GeneratorとDiscriminatorの2つの部分に分けて考えます。(変数説明は最後に記載)
Discriminatorの損失関数:
Discriminatorは、本物 \(D(x_i)\) は1に、偽物 \(D(G(z))\) は0に近づけることを目標としますので、上記の損失関数を最大化することを目指します。
Generatorの損失関数:
Generatorは、\(D(G(x))\) を1に近づけることを目標としますので、上記の損失関数を最小化することを目指します。
最後に、GAN全体の損失関数は、GeneratorとDiscriminatorの損失関数を合わせたものになります。
変数の説明:
- \(x_i\):本物のデータのi番目のサンプル。
- \(z_i\):ランダムノイズのi番目のサンプル。
- \(G(z_i)\):Generatorが生成したデータのi番目のサンプル。
- \(D(x_i)\):Discriminatorが本物のデータのi番目のサンプルに対して出力する値。
- \(D(G(z_i))\):DiscriminatorがGeneratorが生成したデータのi番目のサンプルに対して出力する値。
- \(m\):バッチサイズ。
GANの注意点
GANでは、モード崩壊(mode collapse)と呼ばれる問題が発生することがあります。モード崩壊とは、生成器が複数のモード(パターン)を生成してくれず、単一のモードに収束してしまう現象です。例えば、GANが様々な犬種の画像を生成するように学習した場合、モード崩壊が発生すると、生成される画像はすべて同じ犬種の画像になってしまうことがあります。
モード崩壊の原因は、生成器と識別器のバランスが崩れた場合に発生することが多く、防ぐためには、生成器と識別器のバランスを調整する必要があります(そもそもGANは、学習が安定せず学習が難しい)。また、多様なデータを使用することも重要になります。
また、GANは画像データを1次元のデータに展開して扱うため、位置関係の情報がうまく学習出来ず、生成された画像にノイズが発生します。
基本的なGAN(DCGAN)
DCGAN(Deep Convolutional Generative Adversarial Networks)は、GANのアーキテクチャに畳み込みニューラルネットワーク(CNN)を導入したモデルです。CNNの特性を生かし、画像生成において高品質な結果を得ることができました。
以下にGeneratorの構造を図で示します。
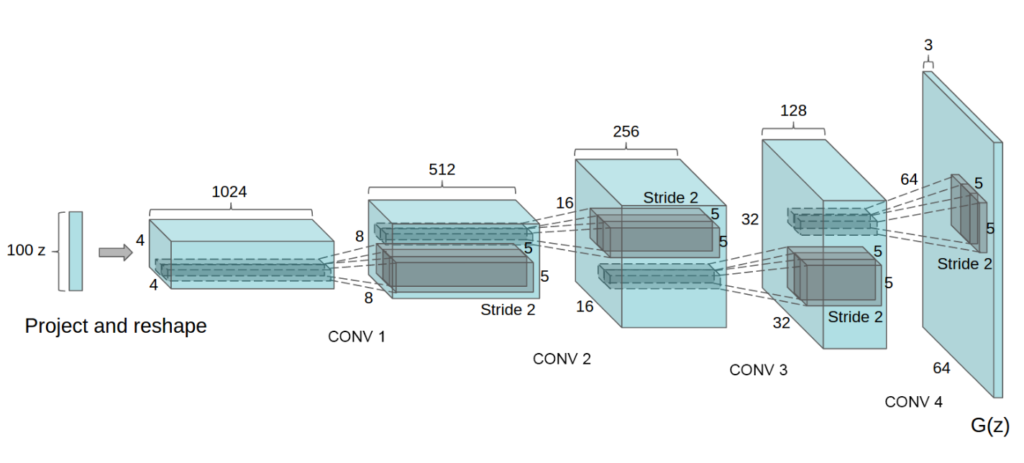
出典: Radford, A., Metz, L., & Chintala, S. (2016). Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks.
arXiv preprint arXiv:1511.06434.
https://arxiv.org/abs/1511.06434 本図は教育目的で引用しています。
特徴
- Discriminator:プーリングの代わりにストライド2の畳み込みを用い、全結合層をGlobal average poolingに置き換えています。また、全ての層で活性化関数にLeaky ReLUを使用し、入力層以外でBatch normalizationを適用しています。
- Generator: Deconvolutionを使ってアップサンプリングを行っています。また、出力層ではtanh関数、それ以外の層ではReLU関数とBatch normalizationを使用します。(全結合層やプーリング層は使われていない。)
- 安定性: DCGANは、通常のGANよりも学習が安定し、高品質な画像を生成しやすい傾向があります。
基本的なGAN(Wasserstein GAN)
Wasserstein GAN(WGAN)は、GANの学習における不安定性を解消し、より安定した学習を実現するために提案されたモデルです。従来のGANは、GeneratorとDiscriminatorのミニマックスゲームが不安定になりやすく、学習が収束しないことやモード崩壊が問題でしたが、WGANは、Earth Mover's Distance (EM距離)の最小化に焦点を置くことで、この問題を解決しています。
特徴
- EM距離: EM距離は、2つの確率分布間の距離を測る指標であり、WGANではEM距離を最小化することに焦点を当てています。
- 安定性: WGANではモード崩壊の問題が軽減され、生成された画像の多様性が向上しました。
※詳細は複雑のため、ここでは概要の説明にとどめましたが、深堀りしたい方はこちらの元論文をご参照ください。(Wasserstein GANの論文)
条件付きGAN(Conditional GAN)
従来のGANでは、Generatorはランダムノイズを入力としてデータを生成します。しかし、生成されるデータは不確定で、特定のカテゴリや条件に基づいたデータ生成ができませんでした。
条件付きGAN(Conditional GAN)は、GANに条件情報を追加することで、特定の条件下での画像生成を可能にしたモデルです。あるクラスやスタイルを指定して画像生成ができます。

特徴
- Generator: ノイズに加えて、クラスラベルやテキストなどの条件情報をワンホットエンコーディングでGeneratorに入力します(ノイズが50次元、ラベルが2次元であれば、52次元のベクトルを入力)。
- Discriminator:条件(数値ラベル)を入力する必要がありますが、画像データとラベルを直接結合することはできません。そこで、ラベルを画像データと同じサイズに拡張し、一番下の層に埋め込むことで、ラベル情報を利用できるようにしています。(例えば入力画像が28 x 28のカラー画像(3ch)の場合、ラべりが2種類の場合は、最終的な入力の次元(shape)が(3 + 2, 28, 28)となります。)
- 柔軟性: 様々な条件下での画像生成が可能となり、従来のGANよりも応用範囲が広がりました。
条件付きGAN(CycleGAN)
CycleGANは、ペアになっていない画像のドメイン間の変換を行うことを目的としたモデルです。例えば、馬の画像をシマウマの画像に変換したり、夏の写真を冬の写真に変換したりすることができます。

出典: Zhu, J. Y., Park, T., Isola, P., & Efros, A. A. (2017). Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks.
arXiv preprint arXiv:1703.10593.
https://arxiv.org/abs/1703.10593 本図は教育目的で引用しています。
特徴
以下にCycleGANのアーキテクチャを示します。
- \(X\) をGenerator \(G\) で \(Y\) に変換し、\(Y\) の偽物データが本物かどうかをDiscriminator \(D_Y\) が判断します。
- 変換後の \(Y\) をGenerator \(F\) で \(X\) に再変換し、再変換後の \(X\) が元の画像なのか変換後の画像なのかを別のDiscriminator \(D_X\) が判断します。
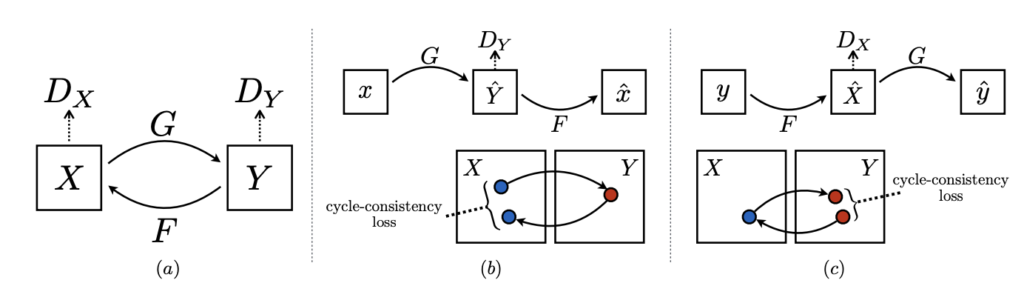
出典: Zhu, J. Y., Park, T., Isola, P., & Efros, A. A. (2017). Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks.
arXiv preprint arXiv:1703.10593.
https://arxiv.org/abs/1703.10593 本図は教育目的で引用しています。
- アーキテクチャ: CycleGANは、2つのGenerator( \( G \) と \( F \) )と2つのDiscriminator( \( D_X \) と \( D_Y \) )を使用して、ペアになっていないデータセット間での変換を行います。
- サイクル一貫性: 変換後のデータが元のデータに戻ることを保証するために、通常のGANで使われる敵対的損失(Adversarial Loss)に加え、サイクル一貫性の損失 Cycle Consistency Loss を導入しています。
- 教師なし学習: ペア画像がなくても学習が可能で、 \( X \) から \( Y \) 、 \( Y \) から \( X \) への変換を行うことで、画像変換を実現します。
関連用語の補足
- pix2pix:画像間の変換を行うためのGANアーキテクチャです。例えば、白黒画像をカラー画像に変換するなど、様々な画像変換タスクに応用されます。ただし、pix2pixではペアになっている画像(例:白黒画像とカラー画像のペア)を用いて学習する必要があります。
キーワードまとめ
識別モデル、自己回帰、生成モデル、拡散モデル、フローベース生成モデル、Denoising autoencoder、VAE、Reparameterization Trick、変分下限、生成器ネットワーク、識別器ネットワーク、モード崩壊 (mode collapse)、Wasserstein GAN、DCGAN、 Conditional GAN、CycleGAN
この分野の理解度をチェック!
最新シラバス対応のオリジナル模試で、本番レベルの問題に挑戦しませんか?
E資格オリジナル模試を見る →